Time series data warehouse as an API
Ingest petabytes and run analytical SQL queries at scale.
So affordable you’ll ask what’s wrong with it.
Have a 100TB+ dataset? Book a consultation
Relied on by the world’s best engineering teams
Get a time series data warehouse as an API without the scaling headache
Ingest petabytes of JSON, NDJSON or MessagePack via HTTP
Run SQL queries via cURL, Metabase or Grafana
Save queries as a client-facing APIs you can securely call from your frontend
Scales beyond

Good fit
Not a good fit
So affordable you’ll ask what’s wrong with it
Benefit from our economies of scale. We pass the savings on to you. Cheaper than self-hosting on AWS.
Ingest up to
5x more data
with the same budget
or save up to
80%
of your costs
Ingest & store a 100 TB dataset, query it 100 times with compute similar to 320 vCPU and 320GB RAM and internet egress of 2x the original dataset
approx.
$16,000
approx.
$16,000
approx.
$43,000
approx.
$43,000
approx.
$56,000
approx.
$56,000
approx.
$62,000
approx.
$62,000
approx.
$85,000
approx.
$85,000
approx.
$116,000
approx.
$116,000
Optimize AWS egress costs
Hosted on AWS? Leverage our ingestion endpoints hosted within AWS so that you don't need to pay AWS $0.09/GB for egress.
We've set up AWS Direct Connect so that you don't have to.
approx.
$4,096
approx.
$4,096
approx.
$9,216
approx.
$9,216
AWS internet egress priced at $0.09/GB. AWS Direct Connect with Better Stack priced at $0.04/GB. Hosted in eu-central-1, if you’re sending data from a different AWS region, you might also need to pay a #0.02/GB inter-region AWS fee.
Simple & predictable pricing
We charge for
Others charge for
Relied on by the world’s best engineering teams
No vendor lock-in:
Open formats in your own S3 bucket
Host your data in your own S3-compatible bucket for full control.
JSON events on object storage, time series on fast NVMe SSD
Get the best of both worlds: scalability and cost-efficiency of wide JSON events stored in object storage, and fast analytical queries with highly compressed time series stored on local NVMe SSD drives.
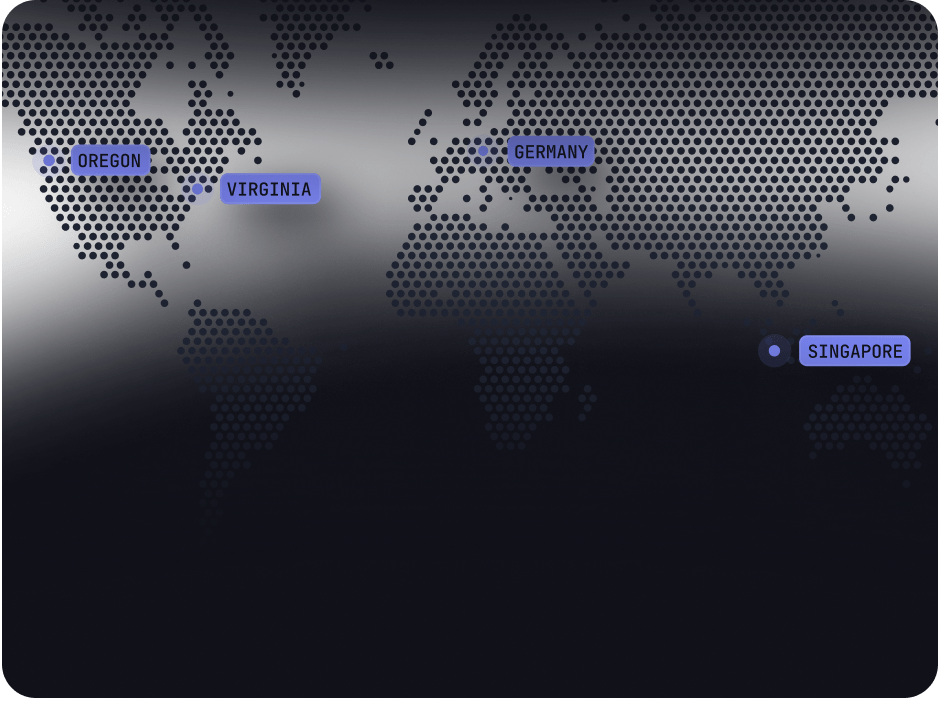
Available in 4 regions, custom deployments on request
Leverage our self-serve clusters in Virginia, Oregon, Germany or Singapore today or request a deployment of a custom cluster with a dedicated S3 bucket in your own VPC.
Run SQL queries with an HTTP API
Your data is yours. Host it in your own S3 bucket and run arbitrary SQL queries via our HTTP API.
Everything you'd expect from a time series data warehouse

Built-in vector embeddings and approximate KNN
Generate vector embeddings without having to call an external API with our built-in embedding model embeddinggemma:300 and query embeddings fast with vector indexes. Run full-text search, multi-vector search and faceted search in a single query.
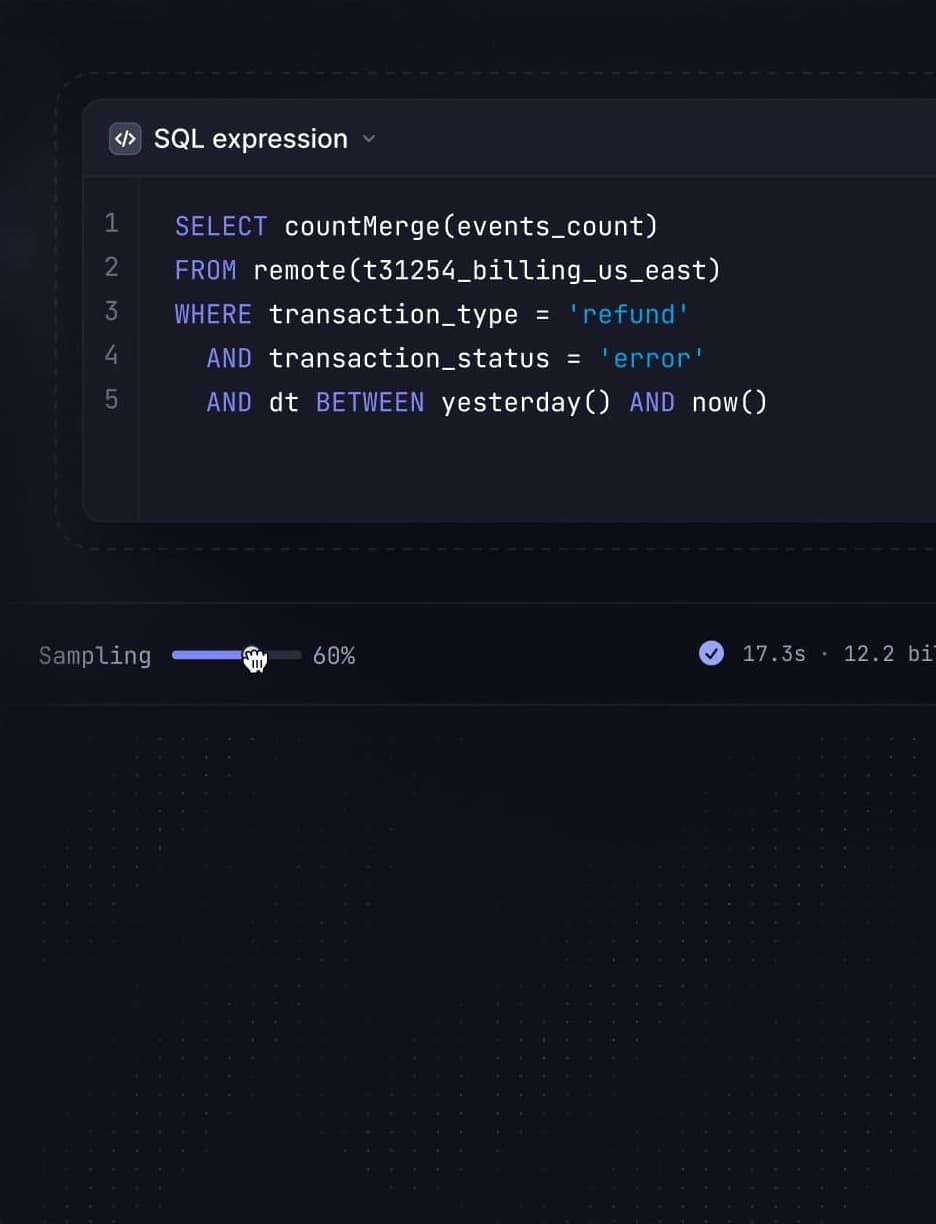
Analyze petabyte-scale trends with query time sampling
Search raw JSON events with 100s of nodes from S3. Run arbitrary SQL queries and leverage query time sampling to get ad-hoc insights about trends at scale or store time series on NVMe SSD for fast analytical queries used in your APIs.
Transform JSON events at scale
Built-in geo IP at query time
Ready-made client-facing APIs
Free of charge.
MCP server
Terraform
Time-to-live
Spending alerts
Detailed usage reporting
Spending limit
Secure, scalable & compliant
Everything your data privacy officer requires so that you can pass audits with a peace of mind.

SOC 2 Type 2

GDPR-compliant

ISO 27001 data centers
Relied on by the world’s best engineering teams
Happy customers, growing market presence
Ship higher-quality software faster. Be the hero of your engineering teams.
Have a 100TB+ dataset? Book a consultation
Please accept cookies
We use cookies to authenticate users, improve the product user experience, and for personalized ads. Learn more.