Tracing reimagined with eBPF & OpenTelemetry
30x cheaper than Datadog. Predictable pricing.
Exceptional customer support.
Datadog bill too high? Migrate today, the rest of your contract is on us.
Migration assistance and bespoke onboarding included.
Book a consultation


Relied on by the world’s best engineering teams
At a fraction of
your current costs
Get an unrivaled price-to-performance ratio. Forget sampling and ingest all your data or decrease your costs by 80x.
Ingest up to
80x more data
with the same budget
or save up to
98%
of your costs
An estimate only. Assumes annual payments, European data location, 1 responder with a Tera bundle, the average event size of 1 kB, $5 per 100 Datadog's "custom metrics". Assumes 1,000 Datadog "custom metrics" equivalent to 1 GB metrics. Further assumes Datadog's $0.1 per ingested GB of spans & logs, and $2.5/million indexed spans & logs for 30 days. Adds up to $51,200 for metrics, $2,787 for logs, and $2,787 for spans per month.
Instrument clusters without code changes thanks to eBPF
Connect your Kubernetes or Docker clusters to gather logs, metrics, and network traces with eBPF. No code changes required.
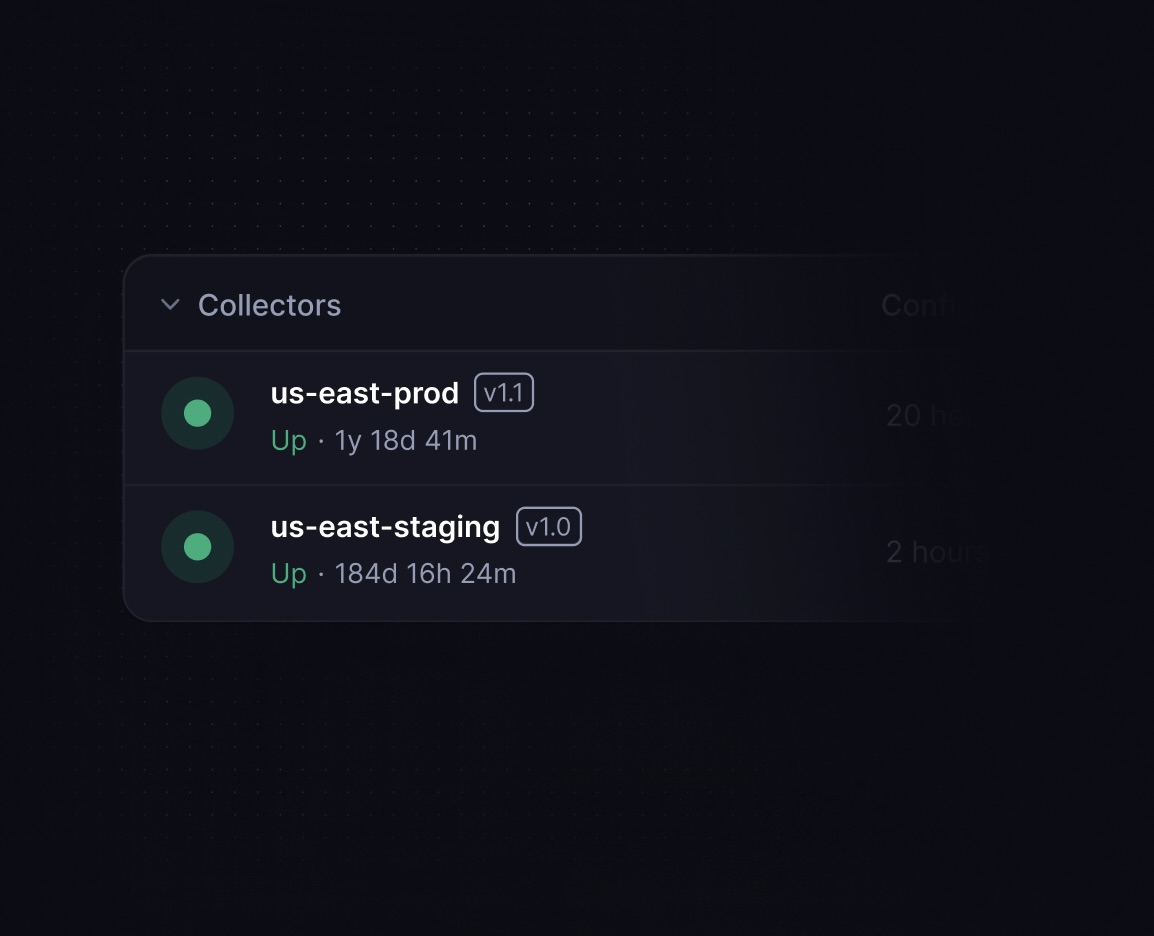
Ship logs with our remotely controlled eBPF collectors
Leverage our remotely controlled collector to gather logs, metrics, and traces using eBPF and OpenTelemetry. Remotely monitor collector’s throughput and adjust sampling, compression, and batching as needed.
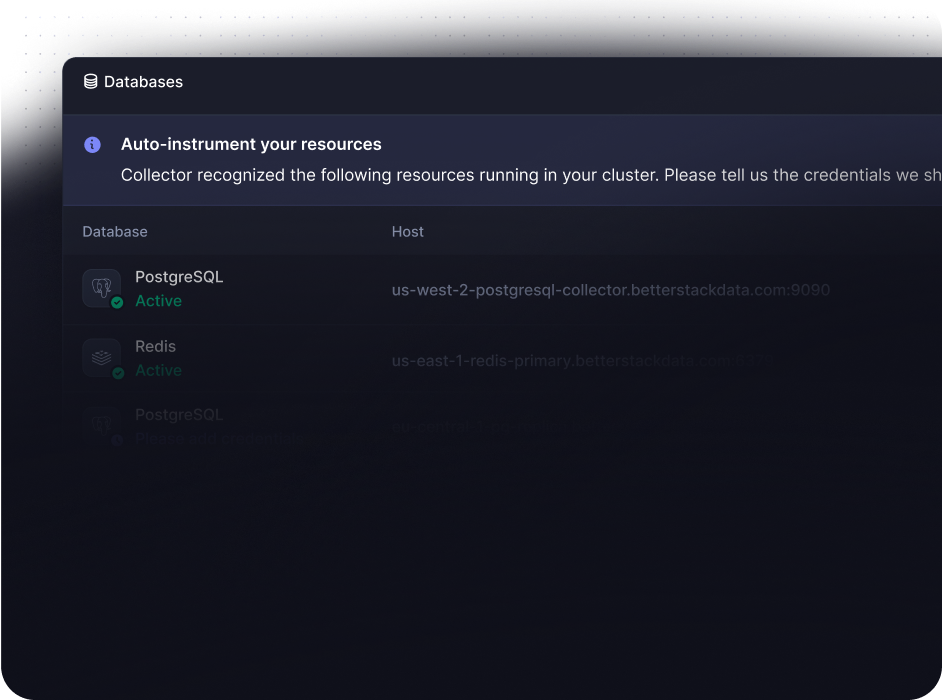
Databases auto-instrumented automatically
Collector automatically recognizes databases
running in your cluster. Monitor the internals of your PostgreSQL, MySQL, Redis, Memcached or
MongoDB out-of-box.
Transform wide events with VRL
Transform logs, spans or other wide events to redact personally identifiable information or simply discard useless events so that you don’t get billed.
Get an AI SRE
Claude Code with the knowledge of your infrastructure.
Give LLMs the power of your telemetry data.
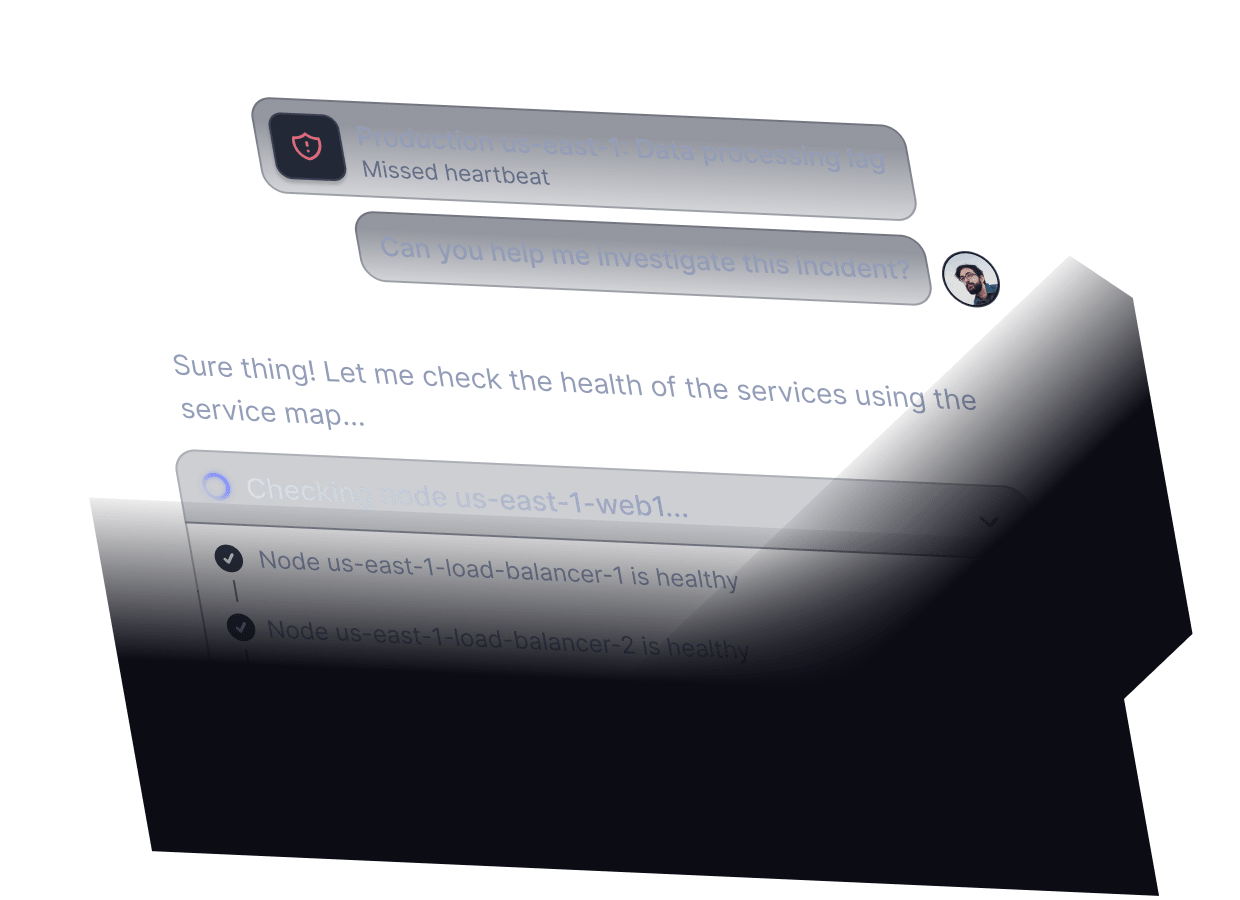
Get an AI SRE to resolve
incidents with you at 3 am
Leverage automated root cause analysis based on the eBPF-based service map & log analysis. You’re always in charge.
Robust MCP server
Integrate your telemetry data into your existing LLM workflows with a top tier MCP server.
You’re always in control
The AI SRE suggests hypotheses but never takes any automated actions without your approval. Get help when investigating an incident while remaining in charge.
Built for OpenTelemetry
Future-proof your applications with OpenTelemetry-native observability. Retain the option to change vendors, and optimize costs as needed. You’re in charge.
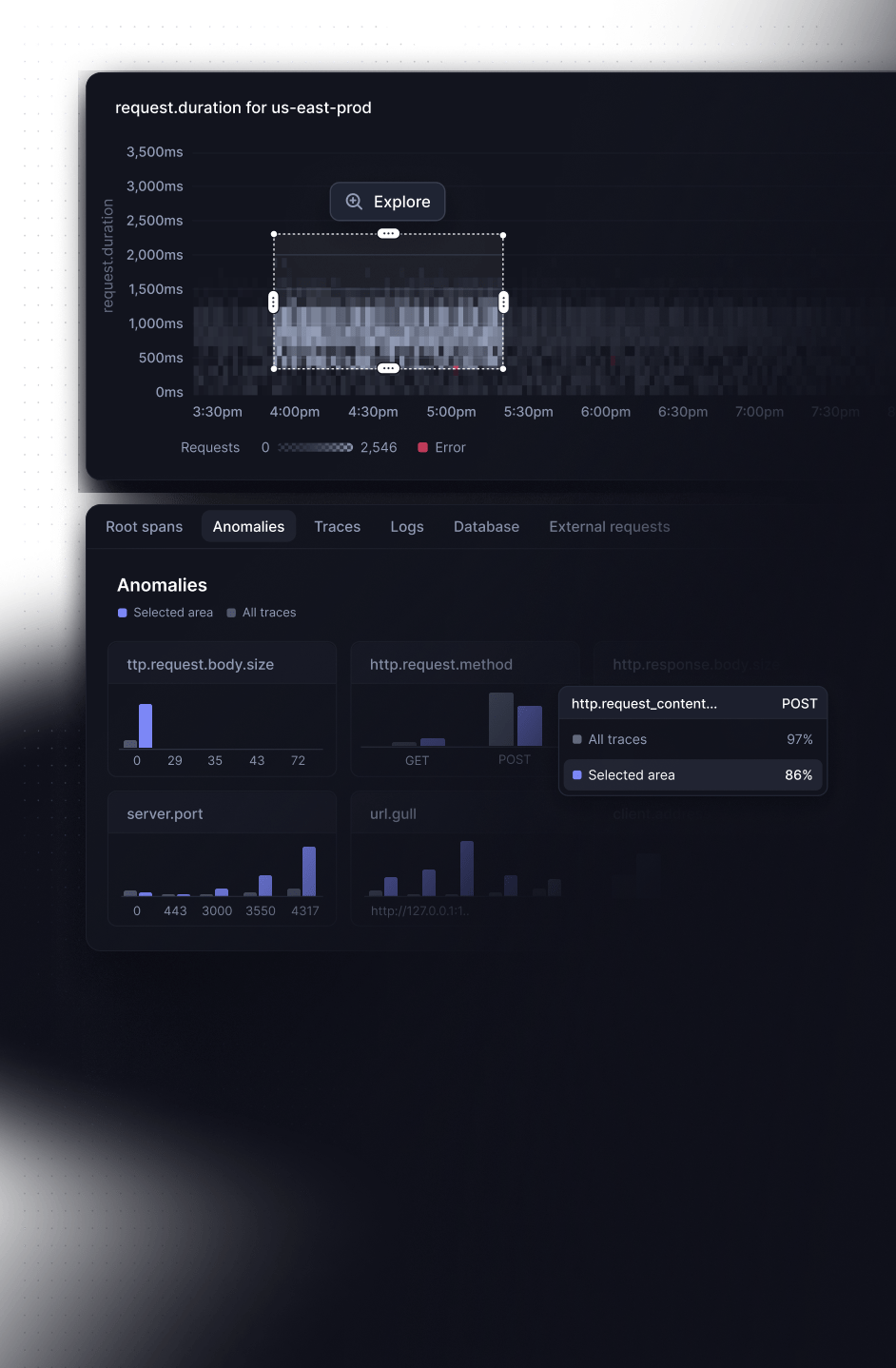
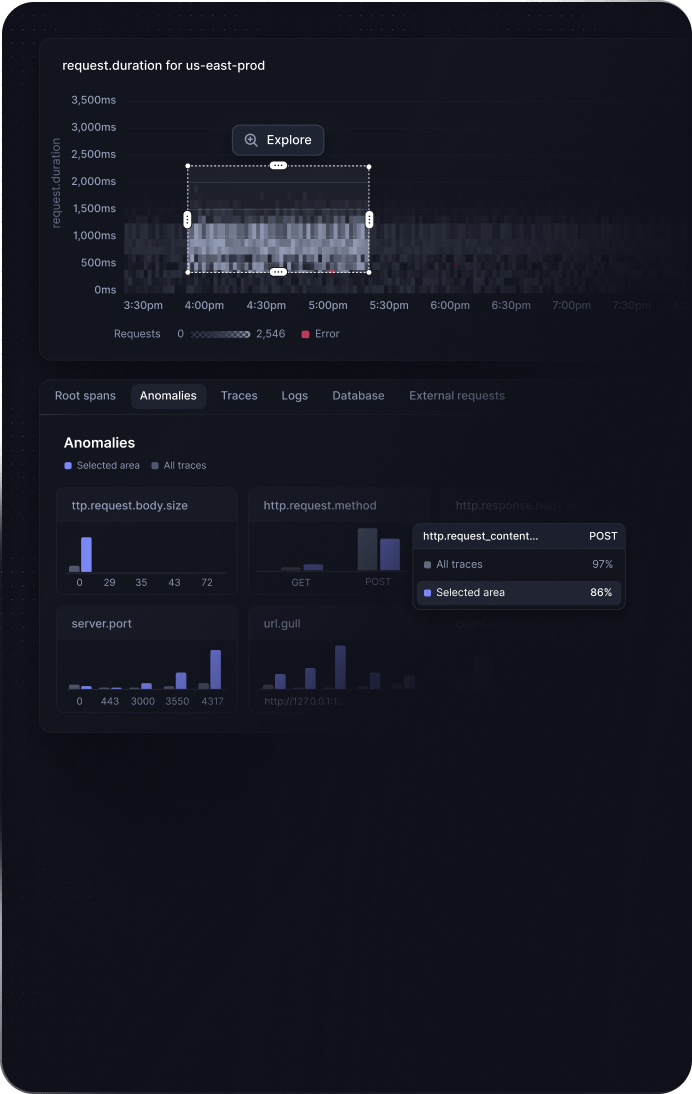
Explore with “bubble up”
Investigate slow requests visually with drag & drop. Simply select the right services and timeframe to instantly see the root cause of slow requests.

eBPF-based service map
Monitor network flows, auto-instrument databases, and track SLOs of individual services. Everything out-of-box with the Better Stack collector.
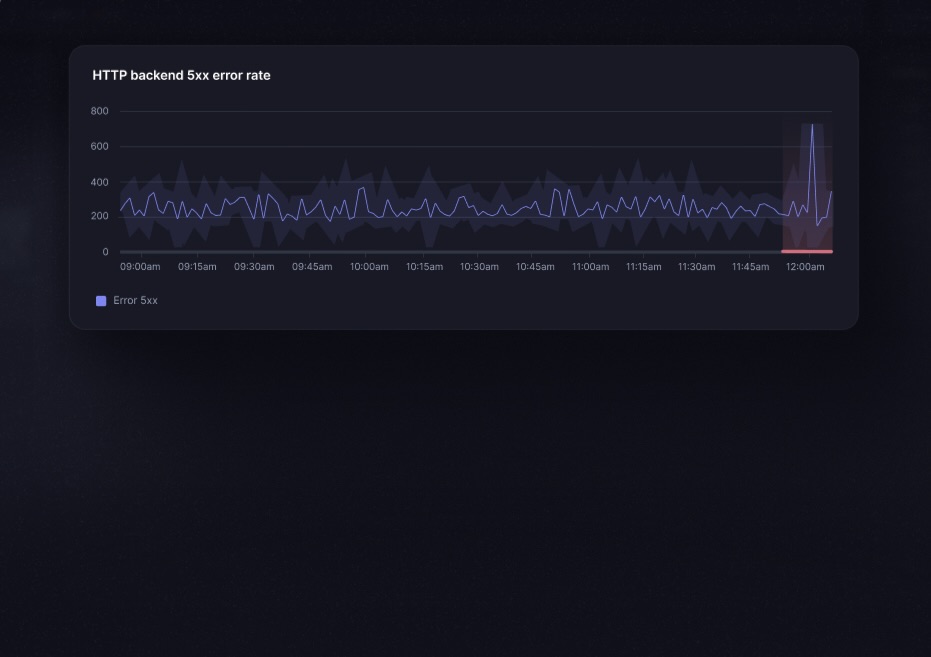
Sophisticated anomaly detection
Leverage our recommended alerts or the automated anomaly detection and get alerted via Slack, e-mail, phone, SMS, and more. Incident management & on-call is built-in.
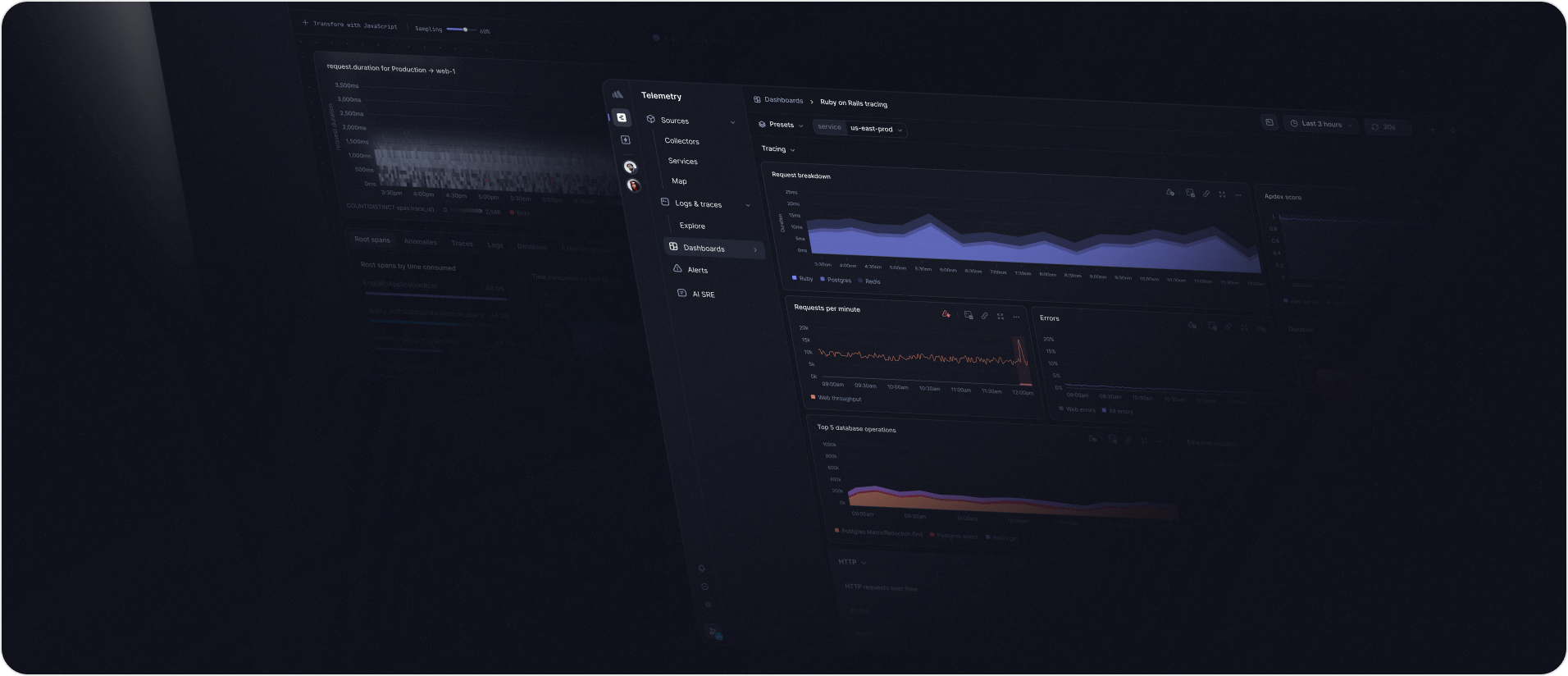
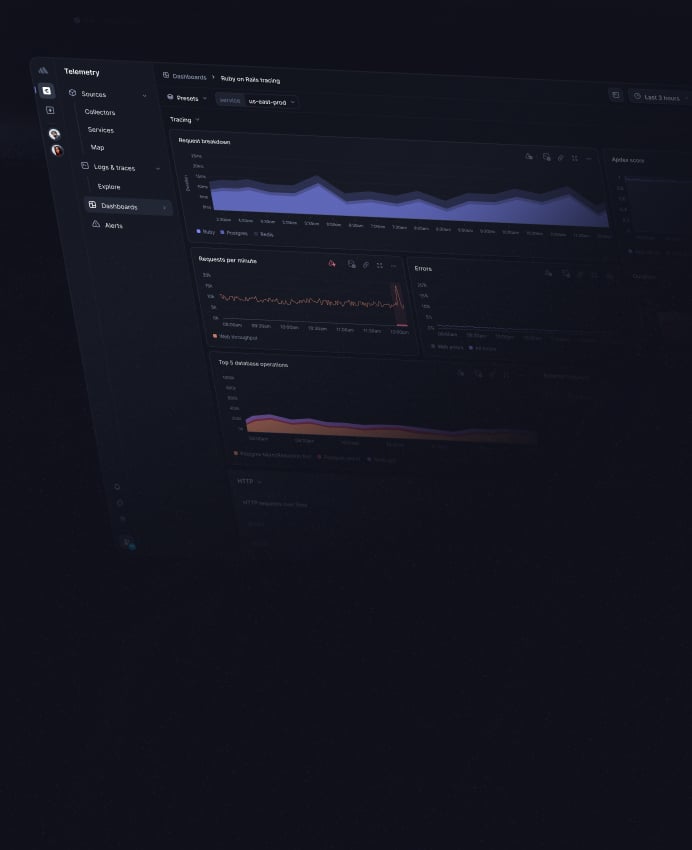
Request breakdown, Apdex, and RED metrics
Everything you need to understand the overall health of a service in a single dashboard.
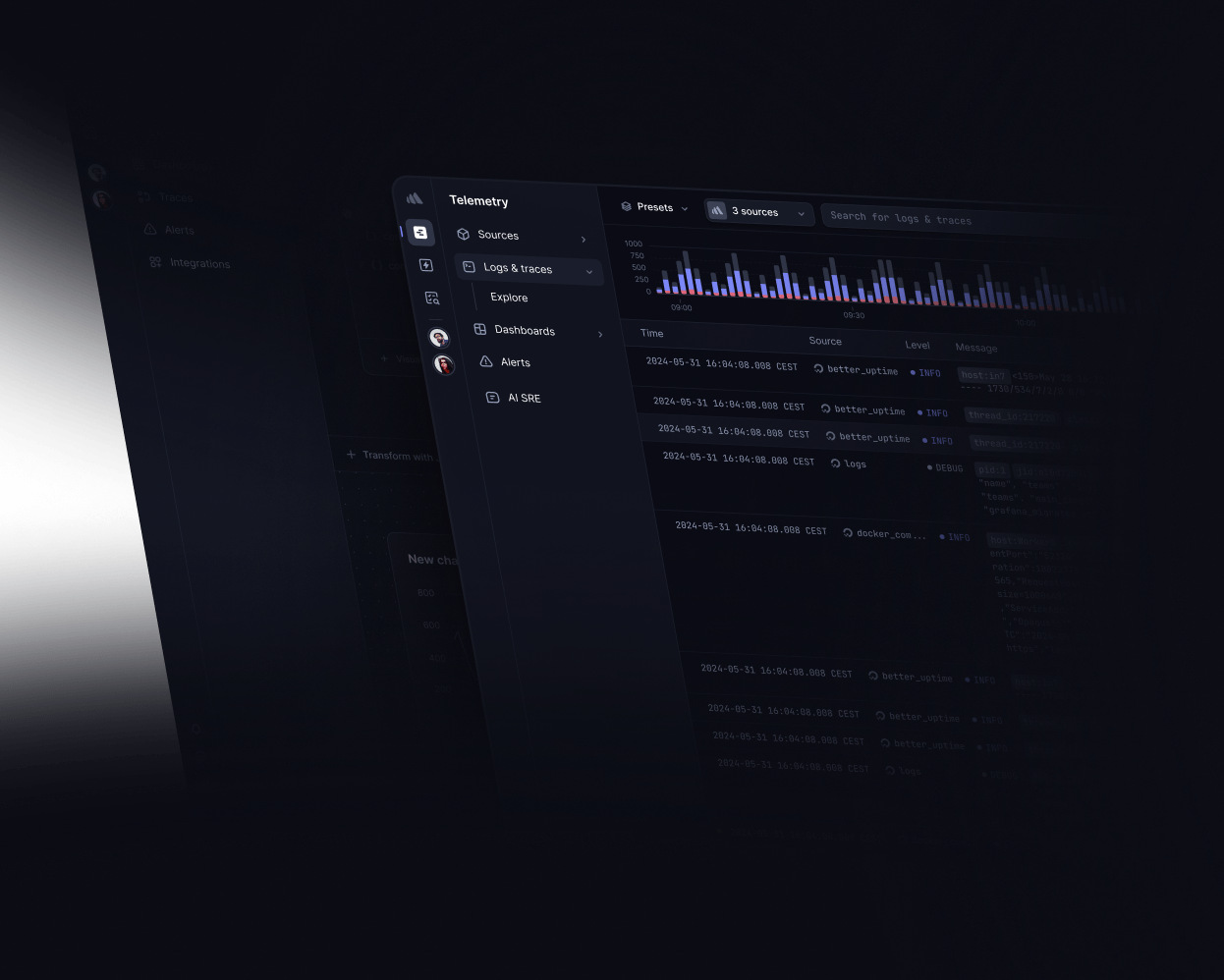
Ingest JSON wide events at scale, get sub-second analytical queries
Powered by a purpose-built data processing pipeline able to process petabytes to exabytes of JSON wide events without cardinality limitations. Get sub-second dashboards, versatile querying APIs at an unbeatable unit cost.
Wide events & time series
Get the best of both worlds: scalability and cost-efficiency of JSON wide events stored in object storage, and fast analytical queries with highly compressed time series stored on local NVMe SSD drives.
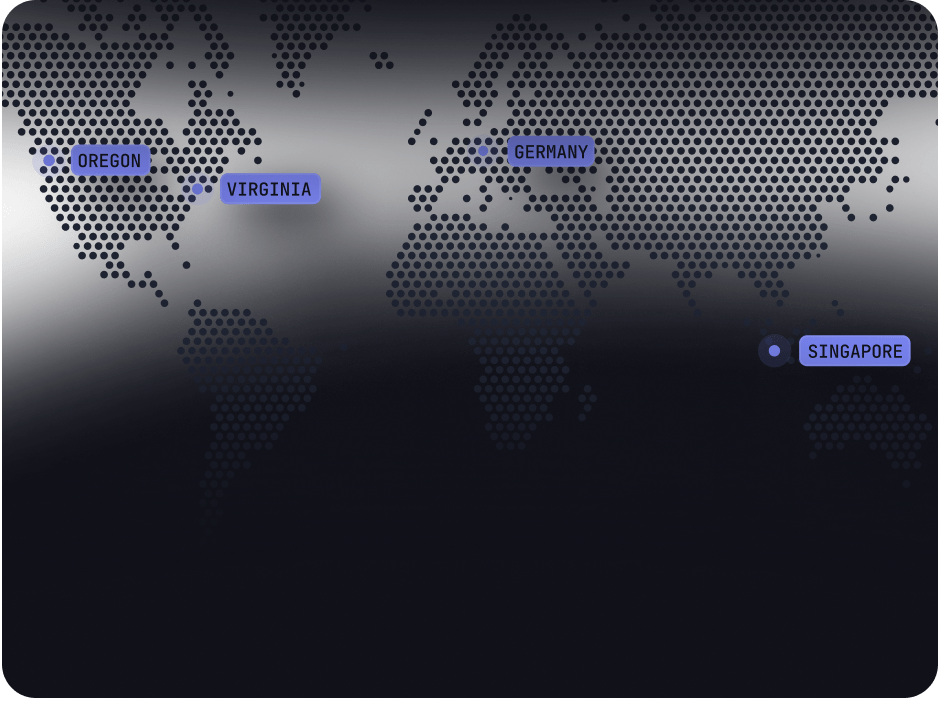
Available in 4 regions, custom deployments on request
Use self-serve clusters in Virginia, Oregon, Germany or Singapore or request a custom cluster with a dedicated S3 bucket in your own VPC.
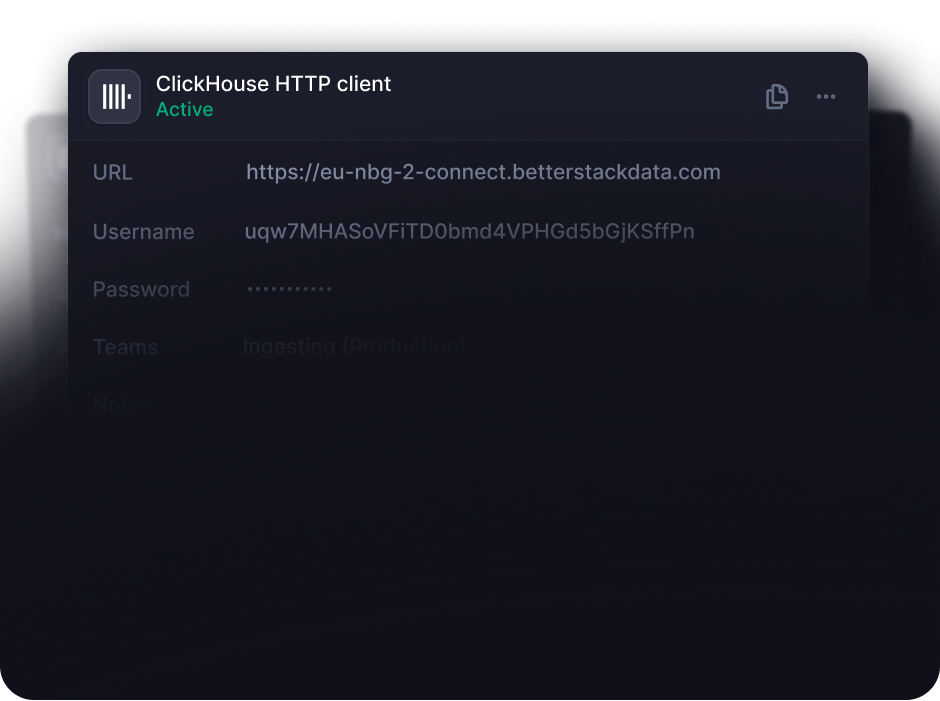
Run any SQL queries via an HTTP API
Think of Better Stack as a data warehouse. Your data is yours. Host them in your own S3 bucket and run arbitrary SQL queries via our HTTP API.
Relied on by the world’s best engineering teams
Happy customers, growing market presence
Ship higher-quality software faster. Be the hero of your engineering teams.
Looking for an enterprise solution? Book a demo
Please accept cookies
We use cookies to authenticate users, improve the product user experience, and for personalized ads. Learn more.