# Better Stack vs Splunk: A Complete Comparison for 2026
Splunk often enters organizations piece by piece. One team adopts it for logs, another adds Observability Cloud, and another runs ITSI. Over time, what looks like a single platform becomes **multiple products, pricing models, and interfaces stitched together**, making cost and complexity harder to manage.
**Better Stack takes a simpler approach.** It brings **logs, metrics, traces, RUM, error tracking, incident management, and status pages into one platform** with a unified data model and volume-based pricing that stays predictable as you scale.
Splunk still has strengths. Its **SIEM and Enterprise Security capabilities are deeply mature**, and ITSI remains a strong option for large-scale service health monitoring. But for teams focused on **full-stack observability and fast incident response**, the gap in cost and operational complexity is hard to ignore.
This comparison breaks down both platforms honestly, including where Splunk clearly leads.
## Quick comparison at a glance
| Category | Better Stack | Splunk |
|----------|-------------|--------|
| **Deployment model** | SaaS only, eBPF auto-instrumentation | SaaS (Splunk Cloud), self-hosted (Enterprise), or hybrid |
| **Instrumentation** | Zero code changes (eBPF) | Agent + SDK per service, or OpenTelemetry |
| **Query language** | SQL + PromQL (unified) | SPL (Splunk Processing Language), per-product |
| **Pricing model** | Data volume + responders | Ingest volume, workload (SVC), entity (per host), or activity-based |
| **OpenTelemetry** | Native, no premium | Supported, OpenTelemetry-native in Observability Cloud |
| **Architecture** | Unified (logs, metrics, traces in one store) | Multi-product (Platform, Observability Cloud, ITSI, Enterprise Security) |
| **Integrations** | 100+ covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more | 2,000+ apps and add-ons via Splunkbase |
| **Enterprise ready** | SOC 2 Type II, GDPR, SSO, SCIM, RBAC, audit logs | SOC 2, GDPR, HIPAA, FedRAMP, PCI DSS |
| **SIEM / Security** | Not available | Full Cloud SIEM, SOAR, UEBA (market-leading) |
| **On-call / Incident** | Built-in ($29/responder/month) | Splunk On-Call (separate SKU), integrates with ITSI |
## Platform architecture
Splunk's platform has accumulated products through over a decade of acquisitions: SignalFx became Splunk Infrastructure Monitoring, VictorOps became Splunk On-Call, and AppDynamics arrived via Cisco's broader purchase of Splunk. The result is a portfolio of capable products that don't always share data models, query languages, or pricing dimensions with one another. Splunk Cloud Platform uses SPL (Splunk Processing Language) for search and analysis. Splunk Observability Cloud uses a separate interface with its own data ingestion pipeline and entity-based billing. ITSI sits on top of Splunk Enterprise or Cloud and adds another configuration and licensing layer.
Better Stack takes the opposite approach: one collector, one query interface (SQL or PromQL), one billing dimension (data volume). Logs, metrics, and traces sit in the same data warehouse, queryable with the same syntax.
### Better Stack: unified telemetry platform
Better Stack's architecture is built on three principles: eBPF-based auto-instrumentation, OpenTelemetry-native data collection, and unified storage. One collector deployed to Kubernetes as a DaemonSet automatically discovers services, captures HTTP and gRPC traffic between them, instruments database queries, and begins building distributed traces — all without touching application code.
**Unified storage** means all ingested data — logs, metrics, traces — lands in the same data warehouse. A single SQL query can join log fields with trace spans and surface the answer in seconds. There are no indexing decisions to make, no tiering strategy to configure, no rehydration lag when you need logs from three days ago.
**Single interface** presents service maps, log streams, metric charts, and trace waterfalls in one view. When an alert fires, all relevant context is immediately visible without switching between products.

### Splunk: multi-product architecture
Splunk's observability portfolio spans several distinct products. **Splunk Cloud Platform** is the core data platform for log ingestion, search, and analysis using SPL. **Splunk Observability Cloud** is a separately licensed SaaS product for infrastructure monitoring, APM, RUM, and synthetic monitoring — billed per host or per activity unit. **Splunk ITSI** is a premium AIOps and service health product that runs on top of Splunk Enterprise or Cloud, adding service KPI monitoring, intelligent event correlation, and episode management. **Splunk On-Call** (formerly VictorOps) handles on-call scheduling and incident notification as yet another separate product.
Each product has its own interface and billing dimension. Investigating an incident that spans logs (Cloud Platform), service performance (Observability Cloud), and on-call status (On-Call) requires navigating between three products, three interfaces, and potentially three contract line items.
What Splunk gains from this architecture is depth. Each product has been developed specifically for its domain, and the Splunkbase ecosystem of 2,000+ apps and add-ons provides integration breadth that few platforms match. Is that depth worth the overhead for your team's use case? That question is worth answering honestly before committing.

| Architecture aspect | Better Stack | Splunk |
|---------------------|--------------|--------|
| **Data collection** | eBPF (zero code) | Agent + SDK per service, or OpenTelemetry Collector |
| **Storage model** | Unified warehouse | Separate per product (Platform, O11y Cloud, ITSI) |
| **Query language** | SQL + PromQL (universal) | SPL for Platform; separate for O11y Cloud |
| **Investigation flow** | Single interface, all context | Navigate across multiple products |
| **Product count** | 1 | 4+ (Platform, O11y Cloud, ITSI, On-Call, ES) |
| **Deployment model** | SaaS only | Cloud, on-premises, hybrid |
| **OpenTelemetry** | First-class native | Native in O11y Cloud; supported in Platform |
## Pricing comparison
Splunk's pricing is one of the most complex in the industry, and its own documentation acknowledges this by offering four distinct models: workload-based (Splunk Virtual Compute units), ingest-based (GB/day), entity-based (per host), and activity-based (per MTS, per trace analyzed per minute, per session). Choosing the wrong model for your data patterns can mean paying significantly more than expected. For Splunk Observability Cloud specifically, entity pricing starts at around **$15/host/month for infrastructure only**, rising to **$60/host/month for infrastructure plus APM** and **$75/host/month for end-to-end observability** (infrastructure, APM, and RUM combined).
For Splunk Cloud Platform (the log management core), ingest pricing ranges from roughly **$150-$225/GB/day** annually at base tiers, based on Vendr transaction data. At 100GB/day of log ingestion, that's $15,000-$22,500/month for the platform alone, before adding observability, ITSI, or security products.
Better Stack's pricing model has one dimension: data volume. You pay for GB ingested and GB stored, at the same rates regardless of host count, cardinality, or which features you use.
### Better Stack: volume-based pricing
Better Stack charges based on actual data volume with no hidden multipliers. The pricing formula is simple: data volume plus responders plus monitors.
**Pricing structure:**
- Logs: $0.10/GB ingestion + $0.05/GB/month retention (all searchable)
- Traces: $0.10/GB ingestion + $0.05/GB/month retention (no span indexing)
- Metrics: $0.50/GB/month (no cardinality penalties)
- Error tracking: $0.000050 per exception
- Responders: $29/month (unlimited phone/SMS)
- Monitors: $0.21/month each
**100-host deployment example:** $791/month
- Telemetry (2.5TB/month): $375
- 5 Responders: $145
- 100 Monitors: $21
- Error tracking (5M exceptions): $250
No cardinality penalties, no high-water mark billing, no indexing tier decisions. Costs scale linearly with actual usage.
### Splunk: multi-model pricing with significant complexity
Splunk's pricing complexity stems from the fact that different products use different billing dimensions, and those dimensions interact unpredictably as usage grows.
**Splunk Observability Cloud (entity pricing):**
- Infrastructure monitoring only: ~$15/host/month
- Infrastructure + APM: ~$60/host/month
- End-to-end (infra + APM + RUM): ~$75/host/month
- Custom metrics: billed per MTS (metric time series), overage fees apply
- Container overages: charged separately beyond subscription allotments
**Splunk Cloud Platform (ingest-based, for log management):**
- Ingest pricing: ~$150-$225/GB/day (annual commitment)
- 100GB/day = ~$15,000-$22,500/month at list price
- Volume discounts available at higher commitments
**Splunk ITSI:** Separate license, workload-based pricing, contact sales
**Splunk On-Call:** Separate seat-based license
**100-host deployment example (O11y Cloud end-to-end):** ~$7,500/month
- 100 hosts at $75/host: $7,500
- Splunk Cloud Platform logs (100GB/day): $15,000+ additional
- ITSI (if needed): additional
- On-Call (if needed): additional
Splunk does offer a Metrics Pipeline Management feature that allows archiving MTS at 1/10th the cost of real-time metrics, which helps manage custom metric costs for teams who need historical data but don't query it frequently. That's a useful cost lever — but it's also an additional configuration burden that Better Stack's volume pricing eliminates.
### Cost comparison: 3-year TCO
For a 100-host deployment over 3 years:
| Category | Better Stack | Splunk |
|----------|-------------|--------|
| Platform (logs, metrics, traces) | $33,600 | $270,000+ (O11y Cloud end-to-end) |
| ITSI / AIOps | Not included | Separate contract |
| Incident management | $5,220 | Splunk On-Call (separate SKU) |
| Engineering overhead | $0 | $30,000+ (configuration, optimization) |
| **Total (O11y only)** | **$38,820** | **$300,000+** |
These estimates assume publicly available list pricing. Actual Splunk costs vary significantly based on negotiated discounts, multi-year commitments (typically 5-7% annual increases on renewals), and which products are bundled. If you're currently evaluating Splunk pricing, what does your contract look like in year 3 after compounding annual increases?
## Application performance monitoring
Both Better Stack and Splunk Observability Cloud are OpenTelemetry-native for APM — meaning they both accept OTel traces as a first-class format without charging a premium. The instrumentation approaches diverge significantly, though. Splunk APM requires installing language-specific agents (Java, Python, Node.js, Go, .NET, Ruby, PHP) and configuring environment variables per service. Better Stack APM captures traces at the kernel level via eBPF, requiring no application changes at all.
### Better Stack: eBPF-based APM
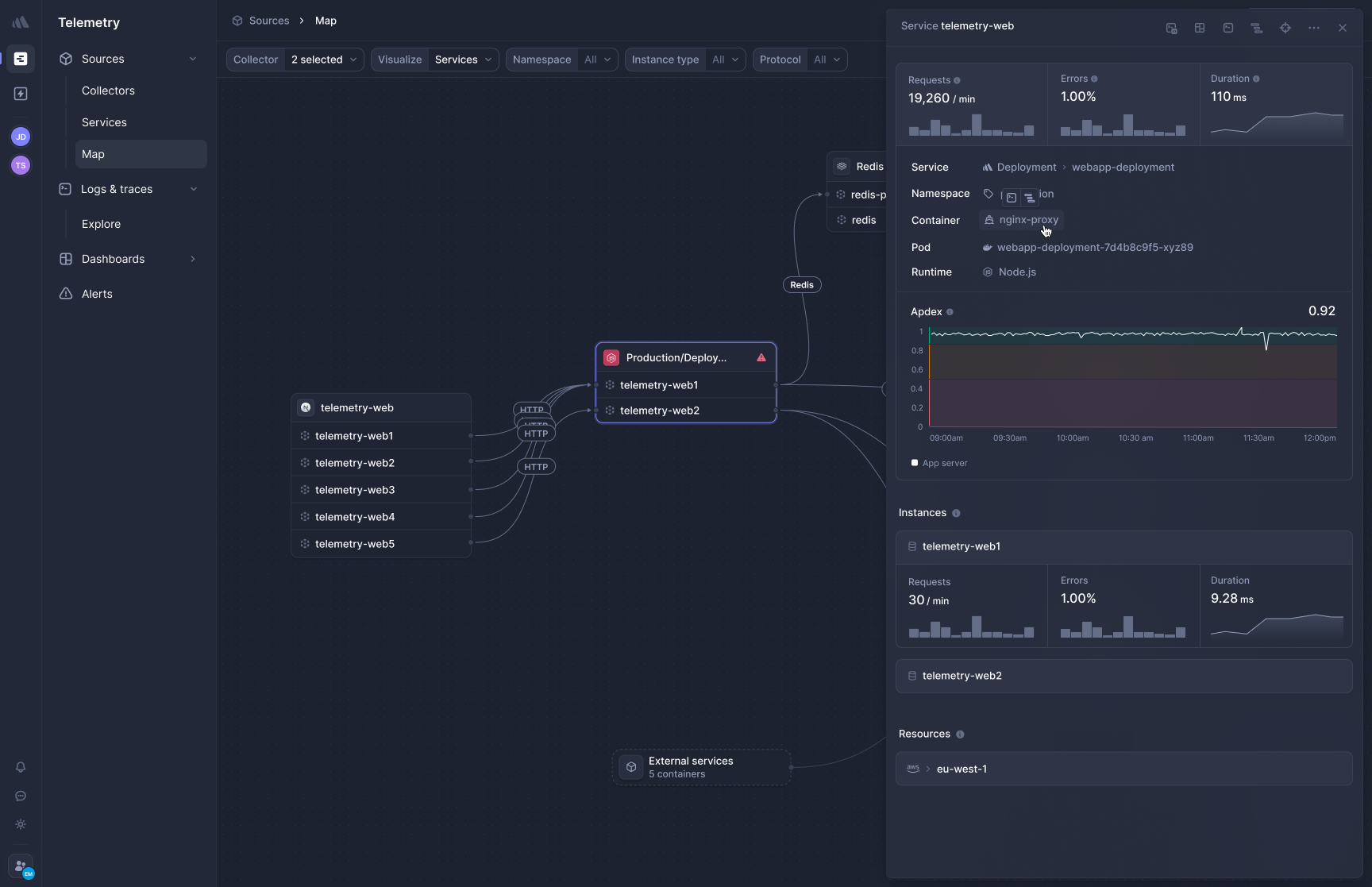
[Better Stack's APM](https://betterstack.com/tracing) captures traces without any SDK installation or code changes. Deploy the collector and HTTP/gRPC traffic between services is traced immediately, along with database queries to PostgreSQL, MySQL, Redis, and MongoDB.
**Frontend-to-backend correlation** connects RUM session data with backend traces in the same interface. A slow page load traces through your microservices and database calls in one view, without switching products or correlation configuration.
**OpenTelemetry-native and zero lock-in.** Traces use the OTel format natively. If you send traces elsewhere tomorrow, you change a config line — not your codebase. No proprietary agents to maintain, no migration tax to pay.
The zero-code approach has a practical advantage in polyglot environments. A stack running Python, Go, Java, and Ruby simultaneously means four sets of tracing SDKs to install, version, and maintain. The eBPF collector handles all four with the same deployment.
### Splunk: full-fidelity APM with code-level profiling
Splunk APM captures every span and trace — it calls this "NoSample" end-to-end visibility — collecting full-fidelity data across all services connected to Observability Cloud. That completeness is a genuine strength: no sampling means no blind spots, and no decisions about what percentage of traces to keep.
**AlwaysOn Profiling** is a meaningful differentiator. Splunk APM includes continuous CPU and memory profiling for Java, .NET, and Node.js — not just network-level tracing, but code-level visibility showing exactly which functions consume CPU and where allocations occur. For teams debugging performance regressions at the code level, this goes deeper than Better Stack's network-level instrumentation.
**Full-stack correlation within Observability Cloud** links APM traces to infrastructure metrics, logs, and RUM in a way that works well once configured. The documentation describes a scenario called "Kai troubleshoots an issue from the browser to the back end" as a canonical flow — indicating the correlation is designed to work across products, though it requires each product to be instrumented separately.
**OpenTelemetry-native** is genuine: Splunk Observability Cloud is built on OpenTelemetry at its core, and OpenTelemetry data is treated as first-class without premium charges. This is a contrast to Datadog, which charges OTel data as custom metrics. Splunk also supports Istio service mesh tracing out of the box.

| APM feature | Better Stack | Splunk |
|-------------|--------------|--------|
| **Instrumentation** | eBPF (zero code) | SDK per language (manual) |
| **OpenTelemetry** | Native, no lock-in | Native, no premium charges |
| **NoSample / full fidelity** | Yes | Yes (NoSample in O11y Cloud) |
| **Code-level profiling** | No | Yes (AlwaysOn: Java, .NET, Node.js) |
| **Database tracing** | Automatic (eBPF) | Manual setup per database |
| **Frontend-to-backend** | Same interface, unified | Requires RUM + APM configured |
| **Istio support** | Via OpenTelemetry | Native |
| **Agent type** | OTel-compatible | OpenTelemetry Collector + language agents |
## Log management
Splunk's original product and core identity is log management. SPL (Splunk Processing Language) is genuinely powerful for log analysis — it's deeply embedded in the operational workflows of security teams, SREs, and DevOps engineers who've spent years learning its syntax. That expertise doesn't transfer easily to a new platform, and for organizations that have built years of searches, dashboards, and alerts in SPL, the switching cost is real.
Better Stack answers the log management question differently: what if logs, traces, and metrics were all queryable with a single language (SQL or PromQL), and all ingested data was searchable at the same cost with no indexing decisions?
### Better Stack: SQL-native log management
[Better Stack logs](https://betterstack.com/logs) stores all ingested logs as structured data in the same warehouse as metrics and traces. Every log is immediately searchable — no indexing tiers, no rehydration, no choosing which logs to make available.
**SQL querying** provides familiar syntax for anyone who has used a relational database:
```sql
SELECT
service_name,
COUNT(*) as error_count,
AVG(duration_ms) as avg_duration
FROM logs
WHERE level = 'error'
AND timestamp > NOW() - INTERVAL '1 hour'
GROUP BY service_name
ORDER BY error_count DESC
```
For frequently used log views, presets save query configurations so your team isn't rebuilding the same filters repeatedly:
**Pricing clarity:** $0.10/GB ingestion + $0.05/GB/month retention. The same 100GB of monthly log data costs $10 ingestion + $5 retention = $15 total.
### Splunk: SPL-native log search at petabyte scale

Splunk Cloud Platform's log management is built for scale. Splunk processes petabyte-scale log data using SPL, with capabilities for real-time streaming, scheduled reports, historical analysis, and correlation across multiple data sources — including security events, infrastructure metrics, and application logs.
**SPL is genuinely expressive** for complex log analysis: multi-step transformations, statistical aggregations, subsearch, lookups against external data sets, and time-series charting. Teams with mature Splunk deployments have built thousands of saved searches, dashboards, and detection rules that encode years of operational knowledge in SPL.
**Flex Index** provides tiered storage: frequently queried data stays in hot storage (fast, more expensive), while historical or rarely-accessed data moves to cheaper cold storage. This gives cost control over retention without losing access to historical data. It's a useful feature — though it adds configuration complexity that Better Stack's flat pricing avoids.
**Log Observer Connect** in Splunk Observability Cloud provides a way to query Splunk Platform logs from within the Observability Cloud interface, bridging the two products. This is an acknowledgment that keeping logs and traces in separate products creates friction during investigations. The bridge works, but it's an integration on top of a split architecture rather than a native unified design.
How many times has your team needed to pivot between the Observability Cloud interface and Splunk's core search interface during a single incident investigation? That transition cost is invisible in licensing comparisons but very visible in time-to-resolution.
| Log management | Better Stack | Splunk |
|----------------|--------------|--------|
| **Query language** | SQL + PromQL | SPL |
| **Searchability** | 100% of ingested logs | Tiered (hot/warm/cold) |
| **Indexing decision** | None (all logs searchable) | Required (affects cost and access) |
| **Trace correlation** | Automatic (same data store) | Log Observer Connect (bridge) |
| **Petabyte scale** | Growing | Established |
| **Ecosystem (saved searches, apps)** | Smaller | 2,000+ Splunkbase apps |
| **Pricing model** | $0.10/GB ingestion | ~$150-$225/GB/day (annualized) |
## Infrastructure monitoring
### Better Stack: no cardinality penalties
[Better Stack metrics](https://betterstack.com/infrastructure-monitoring) uses volume-based pricing regardless of how many unique tag combinations your metrics contain. Add `customer_id`, `deployment_version`, `feature_flag`, and `region` to every metric — the bill reflects total storage size, not the cardinality explosion those tags would create in a per-MTS billing model.
Full PromQL support means existing Prometheus exporters, recording rules, and alerting configurations work without modification. Better Stack also includes a drag-and-drop chart builder for teams who prefer visual configuration over query syntax:
### Splunk: infrastructure monitoring with Metrics Pipeline Management
Splunk Infrastructure Monitoring is built on the SignalFx acquisition and uses MTS (metric time series) as its fundamental unit. In host-based plans, standard host and container metrics are bundled, but custom metrics count against entitlements — with overages billed per additional MTS. Enterprise plans include 200 MTS per host for custom metrics; Standard plans include 100.
For teams with high-cardinality metrics (many unique label combinations), this creates a familiar problem: the tags that make metrics most useful for debugging also make them most expensive to store. Splunk's answer is **Metrics Pipeline Management**, which lets teams route specific MTS to cheaper archive storage rather than real-time storage — a 10x cost reduction on archived metrics. It's a useful tool, but it requires actively managing which metrics are valuable enough to query in real time.
**AI Infrastructure Monitoring** is a notable recent addition: Splunk Observability Cloud now includes dashboards and detectors for AI workloads specifically, covering GPU performance, LLM token costs, model latency, and AI orchestration frameworks. For teams running LLMs or AI agents in production, this is a capability Better Stack doesn't have yet.

| Metrics feature | Better Stack | Splunk |
|-----------------|--------------|--------|
| **Pricing model** | Data volume | Per host + MTS overages |
| **Cardinality** | No penalty | Affects cost (MTS-based) |
| **PromQL support** | Native | Partial (SignalFlow is primary) |
| **Pipeline management** | N/A | Metrics Pipeline Management available |
| **AI infrastructure monitoring** | No | Yes (GPU, LLM, AI agent monitoring) |
| **OpenTelemetry metrics** | Included | First-class in O11y Cloud |
## IT Service Intelligence and AIOps
This is an area where Splunk has no direct analog in Better Stack, and it's worth covering honestly.

**Splunk ITSI** is a premium AIOps product built for IT operations teams managing large, complex service environments. Its core capability is **service health monitoring**: you model your IT services as entities with KPIs derived from metrics, logs, and events, then ITSI monitors service health scores in real time and predicts degradations before they become outages. When issues occur, ITSI automatically correlates related events into episodes, reducing alert noise by up to 95% according to Splunk's own documentation. Episode-based incident management connects to ServiceNow, Remedy, PagerDuty, and other ITSM tools.
For large enterprise IT operations teams managing hundreds of services, business processes, and dependencies, ITSI's service modeling and adaptive thresholding capabilities address a genuine problem. The platform can detect that a degraded database service is about to impact the order processing service, which will impact revenue, and alert on the business KPI rather than the underlying metric — before the outage becomes visible to users.
Better Stack's incident management works well for engineering and SRE teams responding to infrastructure alerts and application errors, but it doesn't offer the service health modeling, KPI monitoring, and predictive AIOps capabilities that ITSI provides. If your team's primary use case is IT service management at enterprise scale, that's a real gap.
| AIOps / ITSM feature | Better Stack | Splunk |
|----------------------|--------------|--------|
| **Service health modeling** | No | Yes (ITSI) |
| **KPI monitoring** | No | Yes (ITSI) |
| **Predictive analytics** | No | Yes (ML-based in ITSI) |
| **Episode management** | No | Yes (noise reduction in ITSI) |
| **ITSM integrations** | Escalate to incidents | ServiceNow, Remedy, PagerDuty (ITSI) |
| **Alert noise reduction** | Monitor deduplication | Up to 95% via ITSI correlation |
## Incident management
Splunk's on-call story involves Splunk On-Call (formerly VictorOps), which handles routing, scheduling, and escalation. On-call is a separate licensed product that integrates with Splunk Cloud Platform alerts, ITSI episodes, and Observability Cloud detectors. Teams that don't purchase On-Call typically route to PagerDuty or OpsGenie instead. Is your current Splunk deployment also running a separate on-call tool? That's a common configuration — and it's an additional cost center that Better Stack folds into the base product.
### Better Stack
[Better Stack incident management](https://betterstack.com/incident-management) includes on-call scheduling, escalation policies, unlimited phone and SMS alerts, and Slack-native incident management — all at $29/month per responder, with no additional tools required.
Incidents create dedicated Slack channels with investigation tools built in, so teams respond without leaving their collaboration workspace:
On-call scheduling includes rotation management, timezone-aware scheduling, and automatic handoffs:
After resolution, Better Stack automatically generates post-mortems from incident timelines:
### Splunk

Splunk On-Call provides on-call scheduling, escalation policies, multi-channel alerting (phone, SMS, push, email), and timeline-based incident collaboration. It integrates with Splunk Cloud Platform alerts, ITSI episodes, and Observability Cloud detectors, creating a coherent alerting flow when configured correctly.
On-Call is a separate seat-based SKU. Teams running Splunk without On-Call typically integrate PagerDuty or OpsGenie, adding another tool to the stack. ITSI's episode management handles intelligent correlation and noise reduction upstream, then hands off to On-Call or an external tool for human notification.
For organizations already running Splunk ITSI, On-Call's integration with ITSI episodes is valuable — the correlation and prioritization that ITSI provides upstream makes on-call rotations more targeted, surfacing only the issues that matter rather than every individual alert. That's a coherent workflow, but it assumes you're already licensed for ITSI.
| Incident feature | Better Stack | Splunk |
|------------------|--------------|--------|
| **On-call scheduling** | Built-in | Splunk On-Call (separate SKU) |
| **Phone/SMS alerts** | Unlimited (included) | Via Splunk On-Call or external tool |
| **Slack integration** | Native incident channels | Integration available |
| **Post-mortems** | Automatic | Manual or via ServiceNow |
| **AIOps correlation** | No | Yes (via ITSI) |
| **Monthly cost (5 responders)** | $145 | Separate On-Call license |
## AI and MCP
Both platforms have moved aggressively into AI-native workflows. The significant development in Q1 2026 is that Splunk's MCP server for Observability Cloud is now generally available — not Preview-only, not allowlisted. This is a meaningful change from the situation six months ago.
### Better Stack: AI SRE and MCP server
**AI SRE** activates autonomously during incidents: it analyzes the service map, queries recent logs, reviews deployment history, and surfaces likely root causes before you've had to prompt it. At 3am, that context makes a material difference.
**Better Stack MCP server** connects Claude, Cursor, and other MCP-compatible AI assistants directly to your observability data. Your AI assistant can run SQL against your logs, check who's on-call, acknowledge incidents, and build dashboard charts through natural language — without you copying and pasting data between tabs.
Setup is a single configuration block:
```json
{
"mcpServers": {
"betterstack": {
"type": "http",
"url": "https://mcp.betterstack.com"
}
}
}
```
Supported operations cover uptime monitoring, incident management, log querying, metrics, dashboards, error tracking, and on-call scheduling. Administrators can allowlist specific tools for read-only access or blocklist destructive operations.
### Splunk: AI Troubleshooting Agent and MCP server
Splunk's AI investment is substantial and accelerating. The Q1 2026 update delivered several capabilities that go beyond Better Stack's current offering in some directions.
**Splunk MCP Server for Observability Cloud** is now generally available. It provides natural language access to Observability Cloud data through the Splunk AI Assistant — including SPL query generation from natural language, search optimization, and direct access to observability telemetry. The MCP server supports Claude Desktop, VS Code, Cursor, and other MCP-compatible clients.
**AI Troubleshooting Agent and Remediation Plan** in Observability Cloud provides root cause summaries during incident investigation: it explains what's happening, why, and suggests how to fix it — directly in context without requiring a separate tool switch.
**AI Agent Monitoring** is now generally available: if you're building LLM-powered applications or AI agents yourself, Splunk can monitor their performance, cost (token economics), and operational health alongside your traditional infrastructure. This is a capability no other platform matches currently, and for teams building AI-powered products, it's genuinely valuable.
**Splunk hosted AI models** (GA February 2026) bring foundation models directly into the platform — including a security-specific model (`Foundation-sec-1.1-8b-instruct`) and general-purpose models (GPT OSS 20B and 120B) — removing the dependency on external AI providers for Splunk's AI features.
**AI Agent Infrastructure Monitoring** includes dashboards and detectors for GPU performance, LLM latency, vector databases (Milvus, Pinecone), and AI orchestration frameworks. Better Stack has no equivalent today.
The MCP server for Splunk Cloud Platform (for SPL search and data exploration) is in beta for both Enterprise and Cloud customers, with the Observability Cloud MCP server at GA. It's worth verifying current availability for your specific deployment region and product.
| AI capability | Better Stack | Splunk |
|---------------|--------------|--------|
| **AI SRE / incident investigation** | Yes (autonomous) | Yes (AI Troubleshooting Agent) |
| **MCP server** | Yes (GA) | Yes (O11y Cloud GA; Platform beta) |
| **AI coding integration** | Claude Code + Cursor | Claude Desktop + VS Code + Cursor |
| **AI agent monitoring** | No | Yes (GA) |
| **LLM/GPU infrastructure monitoring** | No | Yes (AI Infrastructure Monitoring) |
| **Natural language log queries** | Via MCP | Via MCP + AI Assistant |
| **Hosted AI models** | No | Yes (Foundation-sec, GPT OSS — Feb 2026 GA) |
## Real user monitoring
### Better Stack: unified RUM

Better Stack RUM captures frontend sessions, JavaScript errors, Core Web Vitals, and user behavior analytics — all stored in the same data warehouse as backend telemetry. Frontend events and backend traces are queryable with the same SQL syntax in the same interface.
**Session replay** records user interactions with rage click filtering, dead click detection, and 2x playback with automatic pause-skipping. PII is excluded at the SDK level.
**Website analytics** tracks referrers, UTM campaigns, entry and exit pages, and user agent data in real time. **Web vitals** (LCP, CLS, INP) alert when performance degrades below defined thresholds.
**Pricing:** $0.00150/session replay, volume-based, no per-session indexing surprises.
### Splunk: RUM with Digital Experience Analytics
Splunk RUM captures Core Web Vitals, session replays, frustration signals, and user journey analytics. The Q1 2026 update delivered **Digital Experience Analytics** (GA in March 2026): it combines behavioral data with RUM and APM signals to help product, UX, and engineering teams understand user behavior and friction points. The integration uses a single lightweight OpenTelemetry instrumentation agent.
**Mobile RUM** covers iOS, Android, React Native, and Flutter — broader native SDK coverage than Better Stack currently offers for mobile. If mobile application performance monitoring is a core requirement, Splunk has a meaningful advantage here.
**Frontend-to-backend correlation** within Splunk Observability Cloud works through Log Observer Connect: RUM sessions link to APM traces, which link to infrastructure metrics, providing end-to-end visibility when all three products are instrumented. The correlation is well-designed; the prerequisite is that all three products are fully configured.

| RUM feature | Better Stack | Splunk |
|-------------|--------------|--------|
| **Session replay** | Yes | Yes |
| **Core Web Vitals** | LCP, CLS, INP | LCP, FID, CLS + 30 metrics |
| **Mobile support** | Web only | iOS, Android, React Native, Flutter |
| **Digital Experience Analytics** | No | Yes (GA March 2026) |
| **Frontend-to-backend** | Same interface, unified SQL | Via O11y Cloud correlation |
| **Pricing model** | $0.00150/session | Activity-based (per session) |
## Enterprise Security and SIEM
Splunk's Enterprise Security product is the company's most mature and defensible advantage. It's an 11-time Leader in the Gartner Magic Quadrant for SIEM and a Forrester Wave Leader for Security Analytics Platforms as of Q2 2025. If your organization's primary requirement for this evaluation involves threat detection, SOAR, or UEBA, Better Stack is not the right comparison — Splunk Enterprise Security is operating in a different category entirely.
### Splunk Enterprise Security: market-leading SIEM
Splunk Enterprise Security runs on top of Splunk Cloud Platform or Enterprise and provides detection, investigation, and response capabilities at enterprise scale. The product includes SIEM, SOAR (Splunk SOAR), UEBA, Detection Studio, Attack Analyzer, and Exposure Analytics as modular capabilities.
**Detection capabilities** include thousands of out-of-the-box correlation rules, MITRE ATT&CK alignment, User and Entity Behavior Analytics (UEBA) for anomalous behavior detection, and AI-powered triage using Splunk's hosted foundation models. Detection Studio lets security teams develop, deploy, and monitor custom detections without leaving the platform.
**Response automation** via Splunk SOAR provides playbook-driven incident response with 1,000+ pre-configured automation actions across identity providers, cloud infrastructure, endpoints, and third-party tools.
**Attack Analyzer** automates forensic analysis of phishing, malware, and other attack artifacts, reducing the manual effort of separating true threats from noise.
For organizations in regulated industries or those requiring active security monitoring, Splunk's security portfolio is genuinely difficult to replace. The SPL expertise organizations have built for observability transfers directly to security analytics — meaning the platform investment compounds.
### Better Stack: compliance posture
Better Stack is SOC 2 Type II compliant and GDPR compliant, with data stored in ISO/IEC 27001-certified facilities. It offers SSO via Okta, Azure AD, and Google; SCIM provisioning; RBAC; audit logs; AES-256 encryption at rest; TLS in transit; and regular third-party penetration tests with reports available to enterprise customers.
Better Stack has no SIEM, threat detection, SOAR, or UEBA capabilities. It is not HIPAA or FedRAMP compliant. If your evaluation is security-first, Splunk is the more complete platform. If your evaluation is observability-first and your security requirements are compliance certifications rather than active threat detection, Better Stack covers what you need.
| Security and compliance | Better Stack | Splunk |
|------------------------|--------------|--------|
| **SOC 2 Type II** | ✓ | ✓ |
| **GDPR** | ✓ | ✓ |
| **HIPAA** | ✗ | ✓ |
| **FedRAMP** | ✗ | ✓ |
| **PCI DSS** | ✗ | ✓ |
| **SSO/SAML** | Okta, Azure, Google | ✓ |
| **SCIM** | ✓ | ✓ |
| **RBAC** | ✓ | ✓ |
| **SIEM** | ✗ | ✓ (Gartner Leader, 11 consecutive) |
| **SOAR** | ✗ | ✓ |
| **UEBA** | ✗ | ✓ |
| **Threat detection / AI triage** | ✗ | ✓ |
## Deployment and integrations
### Better Stack
Deploy the eBPF collector to Kubernetes via a single Helm chart. The collector runs as a DaemonSet, automatically discovering services and beginning to capture telemetry within minutes. No per-service configuration, no SDK coordination across teams.
OpenTelemetry collectors, Vector pipelines, and Prometheus exporters integrate directly:
Better Stack integrations cover 100+ covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more. The [MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/) is available to all customers.
### Splunk
Splunk's deployment options are more varied: Splunk Cloud (SaaS), Splunk Enterprise (self-hosted on-premises or cloud), or hybrid. This flexibility is a genuine advantage for organizations with data sovereignty requirements, air-gapped environments, or existing on-premises infrastructure investments.
The Universal Forwarder collects logs and metrics from virtually any source and forwards them to a Splunk indexer. Splunkbase's 2,000+ apps and add-ons provide integrations covering virtually every data source, ITSM tool, cloud provider, and security product. For organizations already running Cisco infrastructure, the Cisco-Splunk integration layer adds network visibility, ThousandEyes, and AI POD monitoring as native capabilities.
How many of those 2,000+ integrations does your team actually use? The integration count matters more when you're covering a genuinely diverse data landscape. For teams running standard cloud-native stacks, the 100+ Better Stack integrations likely cover everything relevant.
| Deployment aspect | Better Stack | Splunk |
|-------------------|--------------|--------|
| **Time to first insight** | Minutes | Hours to days |
| **Code changes required** | Zero | Per service (SDK or forwarder) |
| **Deployment options** | SaaS only | SaaS, on-premises, hybrid |
| **Integrations** | 100+ | 2,000+ (Splunkbase) |
| **Air-gapped / on-premises** | No | Yes (Enterprise) |
| **Cisco infrastructure integration** | No | Native |
## Status pages and customer communication
### Better Stack: built-in status pages
[Better Stack Status Pages](https://betterstack.com/status-pages) is built into the platform and synchronizes automatically with incident management. Public and private pages, custom domains, subscriber notifications across email, SMS, Slack, and webhooks, and scheduled maintenance announcements are all included.
**Pricing:** $12-208/month for advanced features, included with Better Stack's incident management at no additional platform cost.
### Splunk
Splunk does not offer a native status page product. Status page functionality typically involves Splunk On-Call's incident timeline features for internal communication, or integration with third-party tools like Statuspage.io. For external customer-facing communication during incidents, most Splunk customers use a separate status page tool.
| Status pages | Better Stack | Splunk |
|--------------|--------------|--------|
| **Native status pages** | Yes (included) | No (third-party integration needed) |
| **Subscriber notifications** | Email, SMS, Slack, webhook | Via third-party |
| **Incident sync** | Automatic | Manual |
| **Custom branding** | Full | Via third-party |
| **Pricing** | $12-208/month | Third-party tool cost |
## Error tracking
### Better Stack

[Better Stack Error Tracking](https://betterstack.com/error-tracking) accepts Sentry SDK payloads, so teams can use Sentry's well-documented SDKs while sending data to Better Stack. AI-native debugging integrates with Claude Code and Cursor via pre-made prompts that summarize error context and full trace information — copy the prompt, paste into your AI coding agent, and resolve without manually reading stack traces.
Every error includes the complete distributed trace for that request, connecting error context to backend behavior automatically.
### Splunk
Splunk Observability Cloud includes error tracking as part of the APM product. Errors link to the traces that caused them, providing full request context alongside stack traces. Error analytics aggregates by service and endpoint, with deployment tracking to correlate error rate spikes with new releases.
For Splunk Platform customers without Observability Cloud, error tracking typically involves log-based alerting on exception patterns using SPL — effective but requiring manual configuration of search patterns and alert thresholds.
| Error tracking | Better Stack | Splunk |
|----------------|--------------|--------|
| **Sentry SDK support** | Yes | No |
| **AI debugging integration** | Claude Code + Cursor | No |
| **Trace context** | Automatic | Integrated with APM |
| **Deployment correlation** | Yes | Yes (O11y Cloud) |
| **Log-based fallback** | N/A | SPL alerting on patterns |
## Enterprise readiness
| Enterprise feature | Better Stack | Splunk |
|-------------------|--------------|--------|
| **SOC 2 Type II** | ✓ | ✓ |
| **GDPR** | ✓ | ✓ |
| **HIPAA** | ✗ | ✓ |
| **FedRAMP** | ✗ | ✓ |
| **PCI DSS** | ✗ | ✓ |
| **SSO (SAML/OIDC)** | ✓ | ✓ |
| **SCIM provisioning** | ✓ | ✓ |
| **RBAC** | ✓ | ✓ |
| **Audit logs** | ✓ | ✓ |
| **Data residency** | EU + US, optional S3 | US, EU, AP; on-premises option |
| **Dedicated support channel** | Slack + named account manager | Enterprise support tiers |
| **SLA** | Enterprise SLA available | Enterprise SLA available |
| **Self-hosted** | No | Yes (Enterprise) |
| **Air-gapped deployment** | No | Yes |
For most enterprise procurement checklists covering SOC 2, GDPR, SSO, SCIM, RBAC, and audit logs, Better Stack satisfies requirements at a fraction of Splunk's cost. The gap appears in regulated industries — healthcare (HIPAA), government (FedRAMP), and financial services (PCI DSS) — and in organizations with air-gapped deployment requirements. Splunk's on-premises option and broader compliance portfolio cover those specific scenarios.
## Final thoughts
If your priority is **modern observability and fast incident response**, **Better Stack is the more practical option**. It brings **logs, metrics, traces, real user monitoring, error tracking, incident management, and status pages into a single platform**, all backed by a **unified data model and predictable volume-based pricing**. You can get started quickly with eBPF-based instrumentation, and the result is **lower operational complexity and significantly reduced cost** compared to a typical Splunk setup.
Splunk, on the other hand, makes more sense when your needs extend beyond observability into **security and enterprise IT operations**. Its **SIEM, SOAR, and ITSI capabilities are deeply mature**, and for organizations with **strict compliance requirements or heavy investment in SPL**, it remains difficult to replace.
If your evaluation is driven by **rising Splunk costs**, the most reliable way to decide is to **run both in parallel**. You can try Better Stack here: [https://betterstack.com](https://betterstack.com)!