# Better Stack vs ServiceNow ITOM: A Complete Comparison for 2026
ServiceNow ITOM is designed around a very enterprise assumption: **operations revolve around the CMDB**. Discovery, service mapping, incident workflows, governance, approvals, and ITSM processes all connect back to that central system of record. For large organizations managing hybrid infrastructure, legacy systems, and strict operational governance, that model can work extremely well.
But it also comes with weight. ServiceNow ITOM is not a lightweight observability platform teams spin up in an afternoon. It is typically part of a broader enterprise transformation project involving ITSM, CMDB maintenance, workflow configuration, and multiple licensed modules.
**Better Stack is optimized for a different kind of team entirely.** Instead of centering governance workflows, it centers **engineering operations and incident response**. With **eBPF-based auto-instrumentation**, teams can start collecting logs, metrics, traces, and infrastructure telemetry without deploying SDKs service by service. **Incident management, on-call scheduling, status pages, error tracking, and observability all live in the same platform**, priced around actual usage instead of organizational structure.
That difference affects both deployment speed and operational overhead.
With ServiceNow ITOM, observability is often one component inside a much larger operational ecosystem.
With **Better Stack**, observability and incident response are the product itself.
ServiceNow still has a clear advantage in environments where **CMDB-driven service mapping, enterprise governance, and deep ITSM integration** are mandatory requirements. But for engineering-led organizations focused on **fast deployment, operational simplicity, and full-stack observability without enterprise complexity**, **Better Stack is the more practical fit**.
This comparison breaks down where each platform aligns best.
## Quick comparison at a glance
| Category | Better Stack | ServiceNow ITOM |
|----------|-------------|-----------------|
| **Deployment Time** | Hours (eBPF auto-instrumentation) | 5+ months average implementation |
| **Instrumentation** | Zero code changes | Agent + CMDB configuration required |
| **Architecture** | Unified (logs, metrics, traces together) | Modular (separate licensed sub-products) |
| **Query Language** | SQL + PromQL (universal) | Module-specific UIs; no unified query layer |
| **Pricing Model** | Data volume + responders | Custom quote; per-seat, per-module, per-node |
| **OpenTelemetry** | Native, first-class | Ingested via connectors; no native OTel query |
| **Integrations** | 100+ covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more | 1,000+ via Integration Hub and Service Graph Connectors |
| **CMDB** | Service-level context via trace/log correlation | Deep, central CMDB with full CSDM |
| **Enterprise Ready** | SOC 2 Type II, GDPR, SSO, SCIM, RBAC | SOC 2, GDPR, HIPAA, FedRAMP, HITRUST |
| **Implementation Cost** | Self-serve; hours to first data | $150,000–$450,000+ in consulting fees alone |
## Platform architecture
The fundamental difference between these two products is what they consider the source of truth. ServiceNow ITOM centers everything on the CMDB: a managed inventory of configuration items (CIs) and their relationships. Infrastructure health, service impact analysis, and incident routing all flow through that CMDB. Better Stack centers everything on telemetry: real-time logs, metrics, and traces captured at the kernel level and stored in a unified data warehouse. Both approaches produce operational visibility. The path to that visibility, and the ongoing cost of maintaining it, are very different.
### Better Stack: telemetry-first unified architecture
Better Stack's architecture is built on three core principles: eBPF-based auto-instrumentation, OpenTelemetry-native data collection, and unified storage. To see how this works in practice, watch how the Better Stack collector automatically discovers services and begins capturing telemetry data without any code changes:
The **eBPF collector** operates at the kernel level, capturing traces, logs, and metrics without application code changes. Deploying to Kubernetes means the collector automatically discovers services, instruments database queries to PostgreSQL, MySQL, Redis, and MongoDB, and builds distributed traces, all without touching your codebase.
**Unified storage** treats logs, metrics, and traces as wide events in the same data warehouse. You query everything with SQL or PromQL without switching between query languages or products. All ingested data is immediately searchable with no indexing fees and no decisions about what to keep searchable.
**Single interface** shows service maps, logs, metrics, and traces together. When an alert fires, all relevant context appears in one view. There's no navigating between separate products to assemble a picture that should have been assembled for you.

### ServiceNow ITOM: CMDB-driven architecture
ServiceNow ITOM builds operational visibility from the bottom up, starting with Discovery (automated CI population), then Service Mapping (dependency relationships between CIs), then Event Management (alert aggregation and correlation from external monitoring tools), and finally the ITOM Health and Service Observability layers on top.
**ITOM Visibility** uses pattern-based, tag-based, and traffic-based discovery to populate the CMDB with configuration items from on-premises servers, cloud instances, network devices, and applications. The Common Services Data Model (CSDM) standardizes how those CIs relate to business services.
**Service Mapping** builds application dependency maps by tracing traffic between CIs and storing those relationships in the CMDB. When an infrastructure component fails, the service map shows which business services are affected and by how much.
**Event Management** sits on top of the CMDB and acts as an aggregator: it ingests alerts from external tools (Dynatrace, Datadog, Splunk, SolarWinds, cloud provider monitors) through Service Graph Connectors and Integration Hub, then applies ML-based correlation and deduplication to reduce alert noise by up to 99% in favorable conditions.
**Service Observability** (the product that brought you to this comparison) aggregates critical signals from those monitoring tools into ServiceNow's Service Operations Workspace, overlaying them on the CMDB service map to give operators a business-impact view of infrastructure health.
What this means in practice: ServiceNow ITOM does not replace your monitoring tools. It aggregates signals from them. You still need Datadog, Dynatrace, CloudWatch, Prometheus, or similar tools generating telemetry. ServiceNow ITOM is the layer that receives, correlates, and routes those signals in the context of your service catalog. Is your team already paying for observability tooling and looking for a workflow layer to orchestrate it? That's ServiceNow ITOM's core use case. Are you looking for an observability platform to replace scattered monitoring tools? Better Stack is the more direct answer.
| Architecture aspect | Better Stack | ServiceNow ITOM |
|---------------------|--------------|-----------------|
| **Data Collection** | eBPF (kernel-level, zero code) | External monitoring tools + Service Graph Connectors |
| **Source of Truth** | Unified telemetry warehouse | CMDB (configuration item relationships) |
| **Query Layer** | SQL + PromQL across all data | Module-specific search; no unified query syntax |
| **Investigation Flow** | Single interface, all context visible | Service Operations Workspace aggregating external tool data |
| **Monitoring Tools Required** | None (Better Stack is the tool) | Yes (ServiceNow aggregates from Datadog, Dynatrace, etc.) |
| **Time to First Insights** | Minutes after deployment | 5+ months of implementation plus CMDB population |
| **OpenTelemetry Support** | First-class native | Ingested via connectors; no native OTel query model |
## Pricing comparison
ServiceNow does not publish pricing. This isn't ambiguity on a public pricing page; it's a deliberate architecture. Every contract is custom-quoted through direct sales, sized against the number of IT fulfillers, the number of managed nodes, the ITOM sub-products included (Visibility, Discovery, Health, Health Log Analytics, Optimization, Cloud Accelerate), and whether you add Now Assist for AI features. You cannot self-estimate a ServiceNow ITOM cost before entering a sales process.
Better Stack pricing is public, volume-based, and predictable. You pay for GB ingested and GB stored, regardless of how many hosts you run, how many teams use the data, or which features you enable. This is not a small operational distinction: it's the difference between knowing your bill before month-end and finding out afterward.
### Better Stack: volume-based, no hidden multipliers
Better Stack charges based on actual data volume with no hidden multipliers. The pricing formula is simple: data volume plus responders plus monitors.
**Pricing structure:**
- Logs: $0.10/GB ingestion + $0.05/GB/month retention (all searchable)
- Traces: $0.10/GB ingestion + $0.05/GB/month retention (no span indexing)
- Metrics: $0.50/GB/month (no cardinality penalties)
- Error tracking: $0.000050 per exception
- Responders: $29/month (unlimited phone/SMS)
- Monitors: $0.21/month each
**100-host deployment example:** $791/month
- Telemetry (2.5TB/month): $375
- 5 Responders: $145
- 100 Monitors: $21
- Error tracking (5M exceptions): $250
No cardinality penalties, no high-water mark billing, no indexing fees. Costs scale linearly with actual usage.
### ServiceNow ITOM: opaque, modular, and consulting-heavy
ServiceNow ITOM pricing operates across several dimensions that make total cost of ownership difficult to estimate before a contract is signed.
**License structure (third-party estimates, not published by ServiceNow):**
- ITOM modules (Visibility, Discovery, Health, HLA, Optimization) each require separate licensing as part of the ITOM bundle
- ITOM Fulfiller roles estimated at $150–$250/user/month (Rezolve.ai, eesel.ai benchmarks)
- Now Assist for ITOM (generative AI) adds roughly 25–60% on top of base license costs
- ITOM node-based pricing varies by the number of managed CIs; large enterprises with tens of thousands of CIs negotiate volume discounts
**Implementation costs (not optional):**
Unlike Better Stack's self-serve deployment, ServiceNow ITOM cannot be implemented without certified partners. Implementation consulting runs $150–$450,000+ for initial deployment, according to multiple third-party assessments. Mid-market deployments (500–2,000 CIs) run $120,000–$300,000 in consulting fees alone before any annual subscription cost. Average G2-reported implementation time: 5 months.
**Ongoing costs:**
- Dedicated ServiceNow administrator: $80,000–$120,000/year salary
- Annual contract uplift: typically 7–10%
- Additional non-production instances (dev, test, staging): often charged separately
- Now Assist AI actions ("Assists") consumed per AI-generated summary or workflow step, with overage charges when the included pool runs out
**What makes this genuinely expensive:** ServiceNow licensing is structured so that discovering a needed feature after go-live often requires a new license SKU. G2 reviewers report surprise license requests years after implementation for capabilities they assumed were included. One reviewer described the experience directly: "ServiceNow licensing can feel pretty scummy... basically unknowable license rules (even by their own reps)."
For organizations already deep in the ServiceNow ecosystem, ITOM can be additive value. For teams evaluating observability from scratch, the implementation overhead makes ServiceNow ITOM a different category of investment entirely.
### Cost comparison: 3-year TCO
For a 100-host deployment over 3 years, using third-party ServiceNow cost benchmarks:
| Category | Better Stack | ServiceNow ITOM |
|----------|-------------|-----------------|
| Platform (logs, metrics, traces) | $33,600 | Not included; external tools still required |
| APM/Tracing | Included | Not included; external APM still required |
| Incident management | $5,220 | ITSM license required (separate from ITOM) |
| Implementation/consulting | $0 | $150,000–$450,000 (one-time) |
| Dedicated admin | $0 | $240,000–$360,000 (3 years) |
| Annual license (ITOM modules) | Included | $150,000–$600,000+ (varies by CI count) |
| **Estimated 3-year total** | **~$47,820** | **$600,000–$1,400,000+** |
The ranges for ServiceNow are wide because contract terms vary significantly. The point is that "ServiceNow ITOM" is not a line-item comparison with Better Stack; it's a platform commitment with a total cost that unfolds over years of consulting, administration, and license expansion.
## Service mapping and discovery
Service mapping is one of ServiceNow ITOM's strongest capabilities and one that Better Stack approaches very differently. If your primary operational question is "which configuration items support this business service, and what is the blast radius of this infrastructure change?", ServiceNow has purpose-built tooling for exactly that. If your primary operational question is "why is this service slow right now, and which logs and traces explain it?", Better Stack answers it faster.
### Better Stack: trace-driven service context
Better Stack's approach to service topology comes from distributed traces rather than CMDB relationships. When the eBPF collector captures HTTP/gRPC traffic between services, it automatically builds service dependency maps from observed traffic. No discovery patterns to write, no credential access to configure, no CMDB to maintain.
What you get is a live, automatically-updated view of how your services talk to each other, derived from actual traffic rather than a maintained inventory. The map is always current because it updates in real time from observed traces.
The trade-off is scope. Better Stack's service context is strongest within your instrumented Kubernetes or Docker environment. It does not extend to network devices, SNMP targets, on-premises hardware inventory, or the kind of heterogeneous enterprise estate that ServiceNow Discovery is designed to catalog.
### ServiceNow ITOM: CMDB-driven service mapping
ServiceNow's Service Mapping builds application dependency maps by running Discovery agents that probe the environment for configuration items and then mapping traffic relationships between them. The result is stored in the CMDB using the Common Services Data Model, which provides business context: this application service depends on these servers, these databases, and these network components.
**The strength:** When an infrastructure component degrades, ServiceNow can immediately calculate blast radius. Which business services are affected? Which teams own them? What changes were made recently that might have caused this? The CMDB provides the context that turns a raw alert into an actionable incident with owner, affected service, and related change history attached.
**The challenge:** CMDB accuracy is the single biggest implementation risk in ServiceNow ITOM. G2 reviewers consistently describe discovery as complex to configure and maintain, particularly in environments with strict security controls. One Virima analysis of G2 reviews found: "Discovery is complicated to implement... need to rewrite everything in patterns from WMI to PowerShell." Industry guidance warns that CMDB accuracy below 70% creates a "catastrophic zone" where service maps are convincingly wrong rather than visibly incomplete. Maintaining CMDB accuracy requires ongoing operational discipline that doesn't go away after go-live.
| Service Mapping Feature | Better Stack | ServiceNow ITOM |
|-------------------------|--------------|-----------------|
| **Topology Source** | Live traces (auto-updated) | CMDB (requires discovery maintenance) |
| **Blast Radius Analysis** | Via trace dependency graph | Via CMDB service map (more comprehensive) |
| **Configuration Items** | Application services, databases | Full IT estate (servers, network, cloud, apps) |
| **Ongoing Maintenance** | Automatic | CMDB accuracy requires dedicated effort |
| **Setup Effort** | Zero | Significant (patterns, credentials, agent access) |
| **Change Impact Analysis** | Deployment-correlated traces | CMDB change history + impact analysis |
## Event management and alert correlation
Alert noise is where many observability teams lose hours they can't recover. Both platforms address it, but from different positions: Better Stack reduces noise by unifying data so you're querying the actual signal rather than correlating across separate tools; ServiceNow ITOM reduces noise by ingesting signals from those separate tools and applying ML-based correlation to them.
### Better Stack: unified signal, no aggregation layer needed
Because Better Stack stores logs, metrics, and traces together in one data warehouse, there is no aggregation step. A single alert can carry full context: which service is affected, what the metrics show, what the relevant log lines say, and which traces are implicated. The investigation starts complete rather than starting with a signal that needs enrichment from three other products.
Alert routing goes through Better Stack's monitoring system. Thresholds, anomaly detection, and composite conditions trigger alerts that route to the right on-call person via phone, SMS, Slack, or Teams. No external tool is required for delivery.
### ServiceNow ITOM: ML-driven correlation from external sources
ServiceNow Event Management aggregates alerts from the monitoring tools already in your environment, including Datadog, Dynatrace, SolarWinds, Prometheus, CloudWatch, and Splunk, via pre-built connectors and Integration Hub. Once ingested, it applies:
- **Rule-based filtering** to normalize and deduplicate the incoming event stream
- **ML-based correlation** to group related alerts into actionable alert groups
- **Topology-based correlation** using CMDB relationships to understand which alerts share underlying infrastructure
- **AI-driven deduplication** that, in favorable conditions, can reduce raw event volume by up to 99%
**Now Assist for ITOM** adds generative AI on top: it summarizes correlated alerts in plain language, suggests remediation steps based on similar historical incidents, and highlights related knowledge articles. For operators dealing with 10,000+ daily events from a complex enterprise estate, this correlation layer delivers measurable noise reduction.
The honest limitation: ServiceNow Event Management only knows what your monitoring tools send it. If an issue doesn't fire an alert in Dynatrace or Datadog, it doesn't exist in ServiceNow. Better Stack, by contrast, captures all telemetry at the source and can surface issues that never triggered an external alert.

| Event Management Feature | Better Stack | ServiceNow ITOM |
|--------------------------|--------------|-----------------|
| **Alert Sources** | Native telemetry (logs, metrics, traces) | External monitoring tools via connectors |
| **Correlation Method** | Unified data warehouse (no correlation needed) | ML + topology-based correlation across tools |
| **Noise Reduction** | Signal is already unified | Up to 99% in favorable configurations |
| **AI Alert Summaries** | Via AI SRE during incidents | Now Assist for ITOM (requires licensing) |
| **CMDB Context on Alerts** | Service-level context from traces | Full CI hierarchy from CMDB |
| **External Tool Dependency** | None | Yes; requires existing monitoring tools |
## Log management
The gap here is fundamental. Better Stack indexes 100% of ingested logs and makes them immediately searchable via SQL. ServiceNow ITOM's Health Log Analytics (HLA) is an add-on module that analyzes log streams for anomalies and early warning signals, but it is not a general-purpose log search and analysis platform. If log querying and troubleshooting are central to your observability workflow, this distinction matters significantly.
### Better Stack: logs as first-class data
[Better Stack logs](https://betterstack.com/logs) treats all logs as structured data stored alongside metrics and traces. All ingested logs are immediately searchable with no indexing fees and no choosing which logs to make searchable. Watch how Better Stack's Live Tail provides real-time log streaming with powerful filtering capabilities:
**SQL querying** provides familiar syntax:
```sql
SELECT
service_name,
COUNT(*) as error_count,
AVG(duration_ms) as avg_duration
FROM logs
WHERE level = 'error'
AND timestamp > NOW() - INTERVAL '1 hour'
GROUP BY service_name
ORDER BY error_count DESC
```
For frequently used queries and filters, Better Stack lets you save them as presets so you can quickly access common views:
**Pricing transparency:** $0.10/GB ingestion + $0.05/GB/month retention. All logs are searchable at that price, not just a sampled subset.
### ServiceNow ITOM: anomaly detection, not log search
ServiceNow's Health Log Analytics (HLA) is designed for a different purpose than log search. It ingests log streams and applies ML-based anomaly detection to identify early warning signals before they become incidents. The Agent Client Collector for Log Analytics (ACC-L) accelerates deployment of HLA for ITOM Health customers.
What HLA is good at: surfacing unusual log patterns that precede service degradation, without requiring teams to define specific thresholds. If your application logs produce a pattern that historically preceded a memory leak, HLA can learn that pattern and alert before the leak impacts users.
What HLA is not: a log search and analysis platform. You cannot issue arbitrary SQL queries against your logs. You cannot search all logs by text string across a time range during an incident. Ad-hoc log exploration, the kind of work you do when you're trying to understand why something broke, is not HLA's purpose. Teams using ServiceNow ITOM still need a dedicated log management tool (Splunk, Elastic, Datadog Logs) for that workflow. HLA is an anomaly detector, not a log database.
Why does this matter? At 3am during an incident, the most valuable thing is the ability to ask arbitrary questions of your log data. "Show me all 500 errors from the payments service in the last 20 minutes" is a Better Stack query that returns immediately. In ServiceNow ITOM, that same question requires a separate tool.
| Log Management | Better Stack | ServiceNow ITOM |
|----------------|--------------|-----------------|
| **Purpose** | Full log storage, search, and analysis | ML-based anomaly detection on log streams |
| **Searchability** | 100% of ingested logs, immediately | Anomaly-based surfacing; no ad-hoc search |
| **Query Language** | SQL + PromQL | Not applicable (anomaly model output) |
| **Separate Log Tool Required** | No | Yes, for ad-hoc investigation |
| **Pricing** | $0.10/GB ingestion + $0.05/GB/month | Module add-on; separately licensed |
| **Trace Correlation** | Automatic (same data warehouse) | Via external APM tool correlations |
## Infrastructure monitoring
ServiceNow ITOM provides infrastructure visibility through CMDB discovery: it knows what CIs exist, where they are, and how they relate to business services. Better Stack provides infrastructure visibility through metrics collection: it knows what resources are doing, how they're performing, and when something deviates from normal.
### Better Stack: metrics without cardinality anxiety
[Better Stack metrics](https://betterstack.com/infrastructure-monitoring) charges based on data volume, not unique metric combinations. Add tags freely for granular analysis with no cardinality anxiety. Prometheus-compatible, supporting full PromQL queries. Watch how Better Stack makes building metrics dashboards straightforward:
If you are already familiar with Prometheus, Better Stack offers native PromQL support. Here's how to build charts using PromQL syntax:
And if you prefer a visual approach over writing queries, Better Stack also provides a drag-and-drop chart builder:
### ServiceNow ITOM: Metric Intelligence for anomaly detection
ServiceNow ITOM's Metric Intelligence module collects performance metrics from monitored CIs and applies adaptive threshold-based anomaly detection. Rather than requiring teams to set static thresholds, Metric Intelligence learns normal behavior per CI and alerts when metrics deviate from learned baselines.
This is genuinely useful for large, heterogeneous environments where manually configuring thresholds across thousands of CIs is not practical. Metric Intelligence can detect service degradations automatically without requiring an operator to define what "bad" looks like for each component.
The constraint, similar to HLA, is that Metric Intelligence is not a general-purpose metrics query platform. You cannot run PromQL queries against your metrics, build custom dashboards from raw metric data, or explore metric trends across services during incident investigation. Those workflows require your existing APM and metrics tools. ServiceNow ITOM receives metric data and detects anomalies; it does not replace the tools that collect and store metric time series.
| Metrics Feature | Better Stack | ServiceNow ITOM |
|-----------------|--------------|-----------------|
| **Collection Method** | eBPF + Prometheus exporters | From external monitoring tools + ACC-M agent |
| **Query Language** | SQL + PromQL (full support) | Not applicable; anomaly model surfacing |
| **Custom Dashboards** | Yes, from raw metrics | Limited; requires external tool for deep analysis |
| **Cardinality** | No penalty (volume-based pricing) | N/A (metric aggregation model) |
| **Anomaly Detection** | Alert-based thresholds + AI SRE | Adaptive thresholds via Metric Intelligence |
| **Separate Metrics Tool Required** | No | Yes, for ad-hoc analysis |
## Application performance monitoring
Better Stack offers eBPF-based distributed tracing with frontend-to-backend correlation. ServiceNow ITOM does not include an APM product. Cloud Observability (a separate ServiceNow product) provides trace ingestion for cloud-native applications, but it is distinct from ITOM and requires separate evaluation.
### Better Stack: eBPF-based APM with zero instrumentation
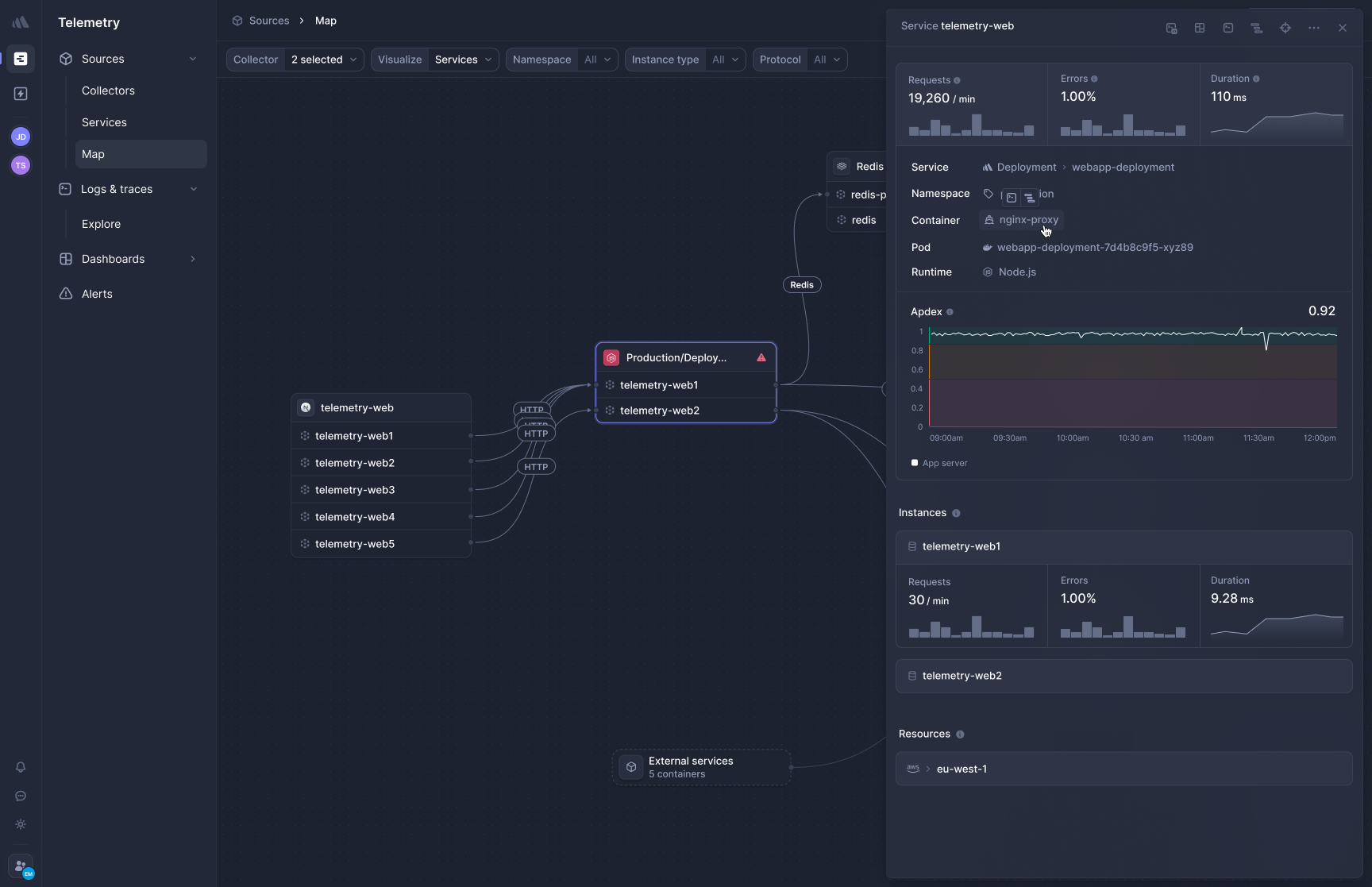
[Better Stack's APM](https://betterstack.com/tracing) uses eBPF to capture traces automatically with no code changes required. Here's how it visualizes and analyzes distributed traces:
Deploy the collector to Kubernetes or Docker, and HTTP/gRPC traffic between services is captured immediately. Database queries to PostgreSQL, MySQL, Redis, and MongoDB are traced automatically.
**Frontend-to-backend correlation** connects what users experience in the browser with what's happening in your backend services. When a page load is slow, you can trace it from the frontend request through your microservices and database calls in one view, without switching products or manually stitching context together.
**OpenTelemetry-native, zero lock-in.** Better Stack treats OpenTelemetry as a first-class citizen. Your traces use the OTel format natively, which means you own your data and your instrumentation. If you ever want to send traces elsewhere, you change a configuration line, not your codebase. No proprietary agents, no SDK lock-in.
### ServiceNow ITOM: APM not included
ServiceNow ITOM does not include distributed tracing or APM. The platform's observability layer receives signals from APM tools (Dynatrace, Datadog, AppDynamics) via connectors and surfaces service health context through the CMDB service map. But the traces themselves, the spans, flame graphs, and request-level latency data that identify slow code paths, live in those external tools.
ServiceNow Cloud Observability is a separate product, acquired via Traceloop (completed 2025), that provides OpenTelemetry-native trace ingestion for cloud-native applications. It integrates with the ServiceNow platform for correlated operations workflows. If APM is part of your ServiceNow evaluation, Cloud Observability is the relevant product to assess independently from ITOM.
| APM Feature | Better Stack | ServiceNow ITOM |
|-------------|--------------|-----------------|
| **Distributed Tracing** | Yes (eBPF, zero code) | Not included (external tool required) |
| **Frontend-to-Backend** | Unified view, one interface | Via external RUM + APM + ITOM correlation |
| **OpenTelemetry** | Native, included | Cloud Observability product (separate) |
| **Database Tracing** | Automatic (Postgres, MySQL, Redis, Mongo) | Via external APM tool |
| **Code-level Profiling** | Network-level only | Via Dynatrace/Datadog integration |
## Incident management
Better Stack includes on-call scheduling, escalation policies, unlimited phone and SMS alerts, and Slack-native incident management at $29/month per responder. ServiceNow's incident management lives in ITSM, a separate product from ITOM. The two are designed to integrate tightly, but they are separately licensed and separately implemented. If you're evaluating ServiceNow for observability-driven incident management, you're evaluating both products.
### Better Stack: full incident lifecycle, no extra products needed
[Better Stack incident management](https://betterstack.com/incident-management) includes unlimited phone/SMS alerts ($29/month per responder), on-call scheduling, escalation policies, and AI-powered investigation with no additional tools required. Here's an overview of how the full incident lifecycle works:
Many teams manage incidents directly in Slack. Better Stack creates dedicated incident channels with investigation tools built in:
On-call scheduling includes rotation management, timezone-aware schedules, and automatic handoffs:
After incidents resolve, Better Stack automatically generates post-mortems from incident timelines:
### ServiceNow: ITSM as the incident layer
ServiceNow's incident management strength is in ITSM, not ITOM. ITOM raises the alert; ITSM opens the incident record, assigns it, tracks it through SLAs, and manages the workflow from triage to resolution. The two products are designed to work together and do so effectively when both are implemented. The integration between ITOM Event Management and ITSM Incident Management is one of ServiceNow's genuine advantages over point-solution observability tools.
What this means for your evaluation: if your organization is already running ServiceNow ITSM for IT service desk operations, adding ITOM to feed it with correlated, CMDB-enriched incidents is a coherent architectural choice. If you're starting without ServiceNow ITSM and evaluating ITOM for observability-driven incident response, you're looking at two implementation projects, not one.
ITSM fulfiller licensing adds $100–$200/user/month to the total cost. For a 20-person operations team, that's $24,000–$48,000/year before ITOM licensing. Better Stack's $29/responder/month for the same team is $6,960/year including phone/SMS.
| Incident Management | Better Stack | ServiceNow ITOM |
|---------------------|--------------|-----------------|
| **Included in Platform** | Yes | Requires separate ITSM product |
| **Phone/SMS Alerts** | Unlimited ($29/responder/month) | Via ITSM; phone/SMS via separate configuration |
| **On-call Scheduling** | Built-in | ITSM On-Call Management module |
| **Slack/Teams Integration** | Native incident channels | ITSM integration |
| **Post-mortems** | Automatic from incident timeline | ITSM problem management workflow |
| **Estimated Monthly Cost (20 responders)** | $580 | $2,000–$4,000+ ITSM fulfiller seats |
## AI operations and MCP
Both platforms are investing heavily in agentic AI. The significant development this month: ServiceNow announced Action Fabric at Knowledge 2026, making its MCP Server generally available and included in every Now Assist and AI Native SKU. This changes the competitive picture. ServiceNow is no longer behind Better Stack on MCP availability; both now offer production-ready MCP integrations.
### Better Stack: AI SRE and MCP server
**AI SRE** is an AI-powered on-call engineer that activates during incidents. It analyzes your service map, queries logs, reviews recent deployments, and suggests likely root causes without requiring you to prompt it manually. During a 3am incident, you start from a hypothesis rather than from scratch.
**[Better Stack MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/)** connects Claude, Cursor, and other MCP-compatible clients directly to your observability data. Instead of copying log snippets into a chat window, your AI assistant can query Better Stack directly: running SQL against your logs, checking who's on-call, acknowledging incidents, or building dashboard charts through natural language.
Setup is a single configuration block:
```json
{
"mcpServers": {
"betterstack": {
"type": "http",
"url": "https://mcp.betterstack.com"
}
}
}
```
From there, you can ask questions like "show me all monitors currently down," "who's on-call right now?", "build a query to find HTTP 500 errors in the last hour," or "create a dashboard showing error rates for my API service."
### ServiceNow: Action Fabric and generally available MCP
ServiceNow's announcement at Knowledge 2026 is substantive. Action Fabric opens the Now Platform to any external AI agent through a generally available MCP Server, included in every Now Assist and AI Native SKU. This means Claude, Copilot, and other MCP-compatible clients can interact with ServiceNow workflows, CMDB records, incidents, and approvals headlessly.
The scope of what ServiceNow's MCP exposes is genuinely broad: every record inside ServiceNow is tied to an action, and those actions are now accessible via MCP. An AI agent can create incidents, update CMDB records, trigger approval workflows, and query operational data across the full ServiceNow platform. Additional MCP features are expected in the second half of 2026.
ServiceNow also introduced an AIOps AI specialist as part of its Autonomous Workforce launch: a purpose-built agent that detects anomalies, correlates events, and triggers remediation workflows. An SRE AI specialist handles incident triage and postmortem documentation. These are significant additions that narrow the AI operations gap with purpose-built observability tools.
The distinction that remains: ServiceNow's AI operates over CMDB context and ITSM workflows. Better Stack's AI SRE operates over live telemetry: actual log lines, trace data, and real-time metric anomalies. These are complementary strengths rather than direct substitutes.
| AI Capability | Better Stack | ServiceNow ITOM |
|---------------|--------------|-----------------|
| **AI SRE** | Yes (autonomous incident investigation over live telemetry) | AIOps AI Specialist (Autonomous Workforce) |
| **MCP Server** | Yes (GA, all customers) | Yes (GA via Action Fabric, Now Assist/AI Native SKUs) |
| **AI Coding Integration** | Claude Code + Cursor | Claude, Copilot, external agents via Action Fabric |
| **Generative AI Summaries** | Via AI SRE during incidents | Now Assist for ITOM (alert summaries, remediation suggestions) |
| **AI Scope** | Live telemetry (logs, traces, metrics) | CMDB records, ITSM workflows, enterprise actions |
| **AI Licensing** | Included | Now Assist requires Pro Plus/Enterprise Plus tier |
## Deployment and integrations
The deployment comparison here is stark. Better Stack deploys in hours. ServiceNow ITOM deploys in months, with mandatory certified partner involvement and a 5-month average implementation timeline per G2 data.
### Better Stack: deploy in hours
Deploy Better Stack's eBPF collector to Kubernetes via a single Helm chart. The collector runs as a DaemonSet on each node, automatically discovering services, capturing traces, and instrumenting databases with no code changes. Here's an overview of how data collection works:
If you're already using OpenTelemetry, Better Stack integrates natively:
For log shipping, Vector integrates directly:
Better Stack connects natively to the tools already in your stack: OpenTelemetry collectors, Vector log pipelines, Prometheus exporters, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more. The [MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/) adds a layer that lets Claude, Cursor, and other AI assistants query your data directly.
### ServiceNow ITOM: months of implementation
ServiceNow ITOM implementation follows a structured program, not a self-serve deployment. Phase one establishes Discovery and CMDB foundations. Phase two adds Service Mapping. Phase three deploys Event Management with connector configuration for each external monitoring tool. Phase four adds Health Log Analytics and Metric Intelligence. Each phase requires certified partner involvement and internal CMDB governance discipline.
**MID Server:** The Management, Instrumentation, and Discovery server is a Java application deployed behind your firewall that enables secure communication between your ServiceNow cloud instance and internal systems. It handles discovery probing, integration hub activity, and CMDB data flows. Configuring MID Server access for diverse infrastructure (Active Directory, databases, cloud APIs, legacy systems) is a significant part of early implementation effort.
**Service Graph Connectors** bring in data from Dynatrace, Datadog, Splunk, SolarWinds, AWS, Azure, GCP, and 1,000+ other sources via Integration Hub. Each connector requires configuration, credential management, and field mapping to CMDB attributes. The integration catalog is comprehensive. The configuration effort per connector varies from hours to days.
Does your team have five months and $150,000+ to get to first value? That's not a rhetorical criticism of ServiceNow; it's a genuine filter question. If the answer is yes, and if CMDB-driven service mapping across a complex enterprise estate is your core use case, the investment delivers real returns. If the answer is no, Better Stack's hours-to-first-data deployment model is a better operational fit.
| Deployment Aspect | Better Stack | ServiceNow ITOM |
|-------------------|--------------|-----------------|
| **Time to First Data** | Hours | 5+ months average |
| **Implementation Required** | Self-serve | Mandatory certified partner |
| **Code Changes** | Zero | CMDB patterns + connector configuration |
| **Average Implementation Cost** | $0 | $150,000–$450,000+ |
| **Ongoing Administration** | Minimal | Dedicated ServiceNow admin recommended |
| **Integration Count** | 100+ (all major stacks) | 1,000+ (via Integration Hub) |
## User experience
### Better Stack: single interface, uniform query language
One interface for logs, metrics, and traces. Same query language (SQL or PromQL) across all data. When alerts fire, all context appears together: service map, logs, metrics, traces, without product switching. You can customize your workspace to match your workflow:
**Investigation workflow:** Alert fires → single view shows service map, related logs, metric anomalies, trace examples → click trace for details. Time to insight: roughly 30 seconds, 2-3 clicks.
Onboarding time for someone new to Better Stack: hours. SQL is a language engineers already know. PromQL has a learning curve, but Better Stack's drag-and-drop chart builder covers most dashboard use cases without it.
### ServiceNow ITOM: powerful, but complex
ServiceNow's interface reflects the depth of its product. The Service Operations Workspace gives operators a centralized view of alert groups, service health, and CMDB context. For experienced operators who understand the CMDB model and have configured dashboards for their environment, it provides genuine operational clarity.
The challenge is the learning curve. G2 reviewers across ITSM and ITOM consistently cite complexity and UI friction as top concerns: "Learning Curve (72)" and "Expensive (60)" are the top two complaint tags across 1,270+ G2 reviews. New users navigate multiple modules, each with its own interface patterns, before reaching productive workflows. One Gartner reviewer summarized: "This tool is pretty full-featured, however it is fairly difficult to use."
G2 also reports that ITOM's power comes with interface trade-offs: some users describe the UI as cumbersome when they only need a narrow slice of the platform's capability. Onboarding to ServiceNow ITOM is measured in weeks to months, not hours.

| UX Aspect | Better Stack | ServiceNow ITOM |
|-----------|--------------|-----------------|
| **Query Language** | SQL + PromQL (unified) | Module-specific UIs; no unified query |
| **Onboarding Time** | Hours | Weeks to months |
| **Investigation Clicks** | 2-3 average | Multiple modules, product-specific navigation |
| **Interface Complexity** | Low (single product) | High (multiple modules, CMDB dependency) |
| **Customization Depth** | Dashboard presets, SQL | Extensive but requires admin expertise |
## Status pages
When a service goes down, the question is whether your users find out from you or from a status dashboard they're already watching. Both platforms offer status page capabilities, but with different scope and integration depth.
### Better Stack: built-in, incident-synchronized status pages
[Better Stack Status Pages](https://betterstack.com/status-pages) is built into the platform and syncs automatically with incident management:
Core capabilities include public and private status pages, custom branding and domains, real-time incident updates automatically synchronized with internal incidents, subscriber notifications via email, SMS, Slack, and webhook, scheduled maintenance announcements, and multi-language support.
**Pricing:** $12-208/month for advanced features, included with Better Stack's incident management at no additional platform cost.
### ServiceNow: status pages via Incident Response suite
ServiceNow offers status pages as part of its Incident Response suite, with component-level tracking, degradation notices, and scheduled maintenance windows. It integrates with ServiceNow Incident Management to publish notices from incident records. Custom domain support and email subscriptions are included.
The constraints compared to Better Stack: status pages in ServiceNow are a separate SKU with pricing that requires contacting sales. Subscriber notifications are email-only; SMS and Slack subscriber notifications are not available. For many DevOps teams, Slack notification is the default channel for external status communication.
| Status Pages | Better Stack | ServiceNow |
|--------------|--------------|------------|
| **Included in Platform** | Yes | Separate SKU (additional cost) |
| **Incident Sync** | Automatic | Via Incident Management integration |
| **Subscriber Notifications** | Email, SMS, Slack, webhook | Email only |
| **Custom Branding** | Full customization + CSS | Custom domains supported |
| **Pricing** | $12-208/month (transparent) | Contact sales |
## Enterprise readiness
Both platforms serve enterprise customers. The meaningful differences are in compliance coverage and implementation model.
Better Stack covers the compliance and access control requirements that most enterprise procurement processes need: SOC 2 Type II, GDPR, SSO via Okta, Azure, and Google, SCIM provisioning, RBAC, audit logs, and data residency options. Enterprise customers also get a dedicated Slack channel for support and a named account manager.
ServiceNow has broader compliance coverage that reflects its position as a system of record for regulated industries. HIPAA, FedRAMP, HITRUST, PCI DSS, and ISO 27001 certifications are available alongside SOC 2 and GDPR. For healthcare, federal government, and financial services organizations with specific regulatory mandates, ServiceNow's compliance portfolio is meaningfully broader.
The other enterprise consideration is organizational fit. ServiceNow is used by 85% of the Fortune 500, often as a central platform for IT, HR, legal, and finance operations. Adding ITOM to an existing ServiceNow estate is a very different decision from adopting ServiceNow as an observability tool from scratch. If your organization already runs ServiceNow, ITOM is a natural extension. If it doesn't, the implementation investment is a standalone commitment.
| Enterprise Feature | Better Stack | ServiceNow ITOM |
|-------------------|--------------|-----------------|
| **SOC 2 Type II** | ✓ | ✓ |
| **GDPR** | ✓ | ✓ |
| **HIPAA** | ✗ | ✓ |
| **FedRAMP** | ✗ | ✓ |
| **HITRUST** | ✗ | ✓ |
| **SSO (SAML/OIDC)** | ✓ | ✓ |
| **SCIM Provisioning** | ✓ | ✓ |
| **RBAC** | ✓ | ✓ |
| **Audit Logs** | ✓ | ✓ |
| **Data Residency** | EU + US regions, optional S3 bucket | US, EU, AP regions |
| **Dedicated Support Channel** | Slack channel + named account manager | Enterprise support tiers + partner ecosystem |
| **SLA** | Enterprise SLA available | Enterprise SLA available |
| **Implementation Model** | Self-serve | Partner-required |
| **Fortune 500 Adoption** | Growing | 85% |
## Final thoughts
ServiceNow ITOM and Better Stack are not direct competitors in the way that two observability-first platforms would be. They answer different questions for different buyers.
**Choose Better Stack if:**
Your team wants full-stack observability across logs, metrics, traces, errors, real user monitoring, and incidents without a 5-month implementation project. You need predictable, volume-based pricing that doesn't require a contract negotiation. Your primary workflow is telemetry-driven: you want to query your data, build alerts, investigate anomalies, and manage incidents from a single unified interface. You're operating Kubernetes or Docker environments where eBPF-based auto-instrumentation removes SDK overhead entirely. Your engineering team is the primary user, and you want tools that fit developer workflows (SQL, PromQL, Claude Code, Cursor integration via MCP).
**Choose ServiceNow ITOM if:**
Your organization is already running ServiceNow ITSM and wants tightly coupled operations where CMDB-enriched incidents flow directly into your existing IT service management workflows. You need a CMDB-driven service map that spans your entire IT estate, including on-premises hardware, network devices, legacy applications, and cloud services. Your primary observability challenge is correlating and routing signals from many existing monitoring tools, rather than deploying a new monitoring tool. You operate in a regulated industry that requires HIPAA, FedRAMP, or HITRUST compliance. You have the budget and timeline for a structured implementation program.
The honest framing: if you're reading this article because you're evaluating observability tools for a developer-facing environment and ServiceNow ITOM appeared on your shortlist, Better Stack is almost certainly the more practical fit. If you're reading this because you're an IT operations leader at a large enterprise deciding whether to add ITOM to your existing ServiceNow investment, the ITSM-ITOM integration story is genuinely compelling for that specific context.
Ready to see Better Stack in action? [Start your free trial](https://betterstack.com) and have data flowing in minutes, not months.