# Better Stack vs Raygun: A Complete Comparison for 2026
Raygun and Better Stack both monitor your applications, but they're solving slightly different problems for slightly different audiences. Raygun is purpose-built for crash reporting and frontend diagnostics, with strong .NET and mobile support, a niche it's been refining for over a decade. **Better Stack is a full-stack observability platform: logs, metrics, distributed traces, real user monitoring, error tracking, incident management, and status pages in one unified system.**
The two products compete most directly on crash reporting and RUM. Where they diverge is everywhere else. If your observability problem is primarily "we need excellent error diagnostics and APM for a .NET or mobile app," Raygun deserves a close look. If your problem is "we need logs, metrics, traces, errors, incident response, and status pages without stitching together four products," **Better Stack is the more complete answer.** This comparison covers both honestly.
## Quick comparison at a glance
| Category | Better Stack | Raygun |
|----------|-------------|--------|
| **Core Focus** | Full-stack observability platform | Crash reporting, RUM, APM |
| **Log Management** | Native, SQL-queryable, 100% searchable | Not included |
| **Infrastructure Metrics** | Native PromQL support, no cardinality penalties | Not included |
| **Distributed Tracing** | eBPF auto-instrumentation, OTel-native | Limited APM (server-side only) |
| **Crash/Error Reporting** | Native, Sentry SDK compatible | Core product, deep diagnostics |
| **Real User Monitoring** | Yes, unified with backend data | Yes, standalone product |
| **Incident Management** | Built-in, $29/responder/month | Not included |
| **Status Pages** | Built-in | Not included |
| **Pricing Model** | Data volume (GB) | Per-event per product |
| **MCP Server** | Yes, GA | Yes, GA (remote, Oct 2025) |
| **AI Features** | AI SRE (autonomous) | AI Error Resolution (prompt-based) |
| **HIPAA** | ✗ | ✓ (BAA available) |
| **OpenTelemetry** | Native, first-class | Not supported |
## Platform architecture
The architectural gap between these two products is substantial, and it shapes everything from your investigation workflow to your monthly bill. Better Stack was built as a unified data warehouse for telemetry. Raygun was built as a specialized diagnostics tool for application errors and performance, and that origin still defines what it is today.
### Better Stack: unified observability

Better Stack's collector operates at the kernel level via eBPF, capturing logs, metrics, and distributed traces from your services without code changes. Watch how the collector deploys and begins discovering services automatically:
Once the collector is running, everything lands in a single data warehouse queryable with SQL or PromQL. There is no separate product for logs, a separate product for traces, a separate product for metrics. When an alert fires, you see service topology, log context, trace details, and metric anomalies in one interface. **Investigation starts immediately rather than being preceded by navigation.**
The platform is OpenTelemetry-native: data is stored in open formats, traces use the OTel specification, and you can redirect your telemetry elsewhere by changing a config line. No migration tax, no vendor-specific SDK to decommission.
### Raygun: specialized application diagnostics

Raygun's architecture reflects its history as a crash reporting tool that expanded incrementally into APM and RUM. Each product (Crash Reporting, Real User Monitoring, APM) is a separate module with separate pricing, separate event quotas, and separate billing dimensions. They share a UI and can cross-reference data, but they're not unified in the same sense as Better Stack's warehouse model.
What Raygun does exceptionally well within those modules: rich crash diagnostics with full stack traces, breadcrumb trails, environment details, affected user counts, and release-correlated error rates. The flamechart view for APM traces gives you a millisecond-level breakdown of every request. For teams whose primary concern is "why is this specific user crashing and what exactly went wrong in the code," Raygun's diagnostic depth is genuinely impressive.
What Raygun doesn't cover: no log management, no infrastructure metrics, no distributed tracing in the OTel sense, no incident management, no status pages. If your stack needs those things, you're adding separate tools.
| Architecture aspect | Better Stack | Raygun |
|---------------------|--------------|--------|
| **Log Management** | Yes (SQL-queryable) | No |
| **Infrastructure Metrics** | Yes (PromQL) | No |
| **Distributed Tracing** | Yes (eBPF, OTel) | Limited (APM, server traces only) |
| **Error/Crash Tracking** | Yes | Yes (primary product) |
| **Real User Monitoring** | Yes | Yes |
| **Incident Management** | Yes | No |
| **Status Pages** | Yes | No |
| **OpenTelemetry** | Native | Not supported |
| **Query Language** | SQL + PromQL | Custom (per product) |
| **Unified Storage** | Yes (one warehouse) | No (separate per product) |
## Pricing comparison
Raygun and Better Stack use fundamentally different pricing models. Raygun charges per event per product: a certain number of crash errors per month, a certain number of RUM sessions per month, a certain number of APM traces per month, each with its own tier, each billed separately. Better Stack charges for data volume (GB ingested and stored) plus responders and monitors.
The practical effect: Raygun's costs can be predictable within a single module but compound unexpectedly as you add modules and exceed event quotas. Better Stack's costs scale with actual data volume regardless of which products you're using.
### Better Stack: volume-based, unified billing
Better Stack's pricing formula has no hidden multipliers. You pay for bytes in and bytes stored, with responder seats and monitors on top. Every product is included in the same bill.
**Pricing structure:**
- Logs: $0.10/GB ingestion + $0.05/GB/month retention
- Traces: $0.10/GB ingestion + $0.05/GB/month retention
- Metrics: $0.50/GB/month (no cardinality penalties)
- Error tracking: $0.000050 per exception
- Responders: $29/month (unlimited phone/SMS)
- Monitors: $0.21/month each
**100-host deployment example:** $791/month total for logs, metrics, traces, error tracking, incident management, and status pages.
- Telemetry (2.5TB/month): $375
- 5 Responders: $145
- 100 Monitors: $21
- Error tracking (5M exceptions): $250
No event quotas to exhaust. No per-product upgrade tiers. When an error spike hits, you pay for the data volume, not a per-error overage at $0.001 each.
### Raygun: per-event, per-product pricing
Raygun's pricing is structured as reserved event buckets, purchased separately per product and billed annually (33% savings vs. monthly). Additional usage beyond your reserved quota is processed on-demand at overage rates. Here's what the published tiers look like (annual billing):
**Crash Reporting:**
- Basic: $40/month (100,000 errors/month)
- Team: $80/month (200,000 errors/month)
- Business: $400/month (1,000,000 errors/month)
- On-demand overage: $0.001 per error
**Real User Monitoring:**
- Basic: $80/month (100,000 sessions/month)
- Team: $160/month (200,000 sessions/month)
- Business: $800/month (1,000,000 sessions/month)
- On-demand overage: $0.002 per session
**Application Performance Monitoring:**
- Basic: $80/month (100,000 traces/month)
- Team: $160/month (200,000 traces/month)
- Business: $800/month (1,000,000 traces/month)
- On-demand overage: $0.002 per trace
SAML SSO is available as an add-on on lower tiers, or included from the Business plan. There is no free tier; a 14-day trial is available with no credit card required.
**For a team running all three Raygun products at moderate volume (200K events each, annual billing):** approximately $400/month for Crash + RUM + APM combined, before incident management and log tooling costs.
Is the per-event model a problem? Not necessarily, but the math changes at scale. A high-traffic application generating 2 million errors per month exceeds the Business tier and moves to on-demand pricing at $2,000 per additional million errors. Teams have reported unexpected bills during error spikes even with spike protection in place.
**What Raygun doesn't include that has its own cost elsewhere:** log management, infrastructure metrics, incident management (PagerDuty, OpsGenie, or similar), and status pages all need separate tools and separate budgets.
### 3-year TCO: full observability stack (100 hosts)
This comparison models a team that needs logs, metrics, traces, error tracking, incident management, and status pages. For Raygun, gaps are filled with best-of-breed tools. For Better Stack, everything is included.
| Category | Better Stack | Raygun + gaps |
|----------|-------------|---------------|
| Platform (logs, metrics, traces) | $33,600 | $0 (not included; add Datadog/New Relic ~$126,000) |
| Error tracking | $9,000 | $14,400 (Business tier, 3 products) |
| Incident management | $5,220 | $21,600 (PagerDuty) |
| Status pages | Included | $10,800+ (Statuspage.io) |
| Engineering overhead | $0 | $30,000 (configuration, maintenance) |
| **Total** | **$47,820** | **$202,800+** |
This comparison is only fair when scoping a complete observability stack. If your team only needs crash reporting and APM, Raygun's 3-year cost at the Team tier is approximately $5,760 per product, competitive with Better Stack for that narrow use case.
## Crash reporting
Crash reporting is Raygun's flagship product and the one where it genuinely competes on depth. The diagnostics you get from Raygun for a single crash event are detailed: complete symbolicated stack trace, breadcrumb trail of user actions before the crash, environment metadata (OS, browser, app version, device), affected user count, crash frequency over time, and release-correlated trends that show whether a specific deployment introduced the regression.
### Raygun: best-in-class crash diagnostics

Raygun supports crash reporting across web (JavaScript, TypeScript), backend (.NET, Ruby, Node.js, Python, Java, PHP, Go, Elixir), and mobile (iOS, Android, Flutter, React Native, Xamarin). For .NET and Flutter specifically, the depth of diagnostics exceeds most competitors. Flutter support with native symbols was added in 2025, giving automatic deobfuscation for Flutter stack traces.
**AI Error Resolution** is Raygun's AI debugging feature. When you open an error group, Raygun constructs a prompt from the stack trace, environment data, and affected code context, then submits it to OpenAI or Azure OpenAI using your own API key. You get suggested fixes alongside the error. No model training occurs on customer data. Conversation history is retained so teams can discuss a specific error without re-prompting.
**Spike protection** caps incoming error processing during abnormal spikes at 5x your historical rate per minute, preventing a single traffic event from consuming your entire monthly quota in hours.
**Grouping intelligence** clusters similar errors into a single issue regardless of minor stack trace variations, reducing noise and making it easier to identify what actually matters. Teams consistently praise this in reviews as better-than-average compared to competitors.
The honest limitation: Raygun crash reporting is a standalone diagnostic product. It tells you an error happened, shows you the stack trace, and surfaces which users were affected. It doesn't tell you what the underlying infrastructure was doing at the time, what logs were being generated, or how the service request chain looked. That context requires additional tools.
### Better Stack: error tracking connected to everything else
[Better Stack Error Tracking](https://betterstack.com/error-tracking) accepts Sentry SDK payloads, so if you're already instrumented with Sentry's SDKs, switching to Better Stack doesn't require touching your error instrumentation.

**The key difference from Raygun's approach** isn't the error diagnostics themselves. It's what surrounds them. When Better Stack surfaces an error, the full distributed trace for that request is available in the same view. The logs from the same time window are immediately queryable. The infrastructure metrics for the affected service are a click away. The on-call engineer can be paged directly from the error detail.
**AI-native debugging** includes Claude Code and Cursor integration with pre-made prompts that package error context for your AI coding agent. Copy the prompt, paste into your coding assistant, and get resolution suggestions without manually reading through stack traces or assembling context.
For teams already using Sentry, migration to Better Stack preserves SDK instrumentation while gaining the surrounding observability context Sentry doesn't include.
| Crash reporting feature | Better Stack | Raygun |
|------------------------|--------------|--------|
| **SDK Compatibility** | Sentry SDK | Native SDKs |
| **Diagnostic Depth** | Standard | Deep (breadcrumbs, user context, env) |
| **AI Debugging** | Claude Code + Cursor prompts | AI Error Resolution (OpenAI/Azure) |
| **Backend Trace Context** | Automatic (same platform) | Requires separate APM setup |
| **Log Context** | Automatic | Not included |
| **Incident Escalation** | Built-in | Manual/external |
| **.NET Support** | Yes | Industry-leading |
| **Flutter Support** | Yes | Yes (native symbols, 2025) |
| **Mobile (iOS/Android)** | Yes | Yes |
| **Pricing** | $0.000050/exception | $40-$400/mo per event tier |
## Application performance monitoring
Raygun's APM and Better Stack's APM differ more in philosophy than in the features they surface. Raygun APM gives you deep, code-level visibility into server-side request performance. Better Stack APM captures distributed traces across your microservices via eBPF without requiring SDK changes per service.
### Better Stack: eBPF-based distributed tracing
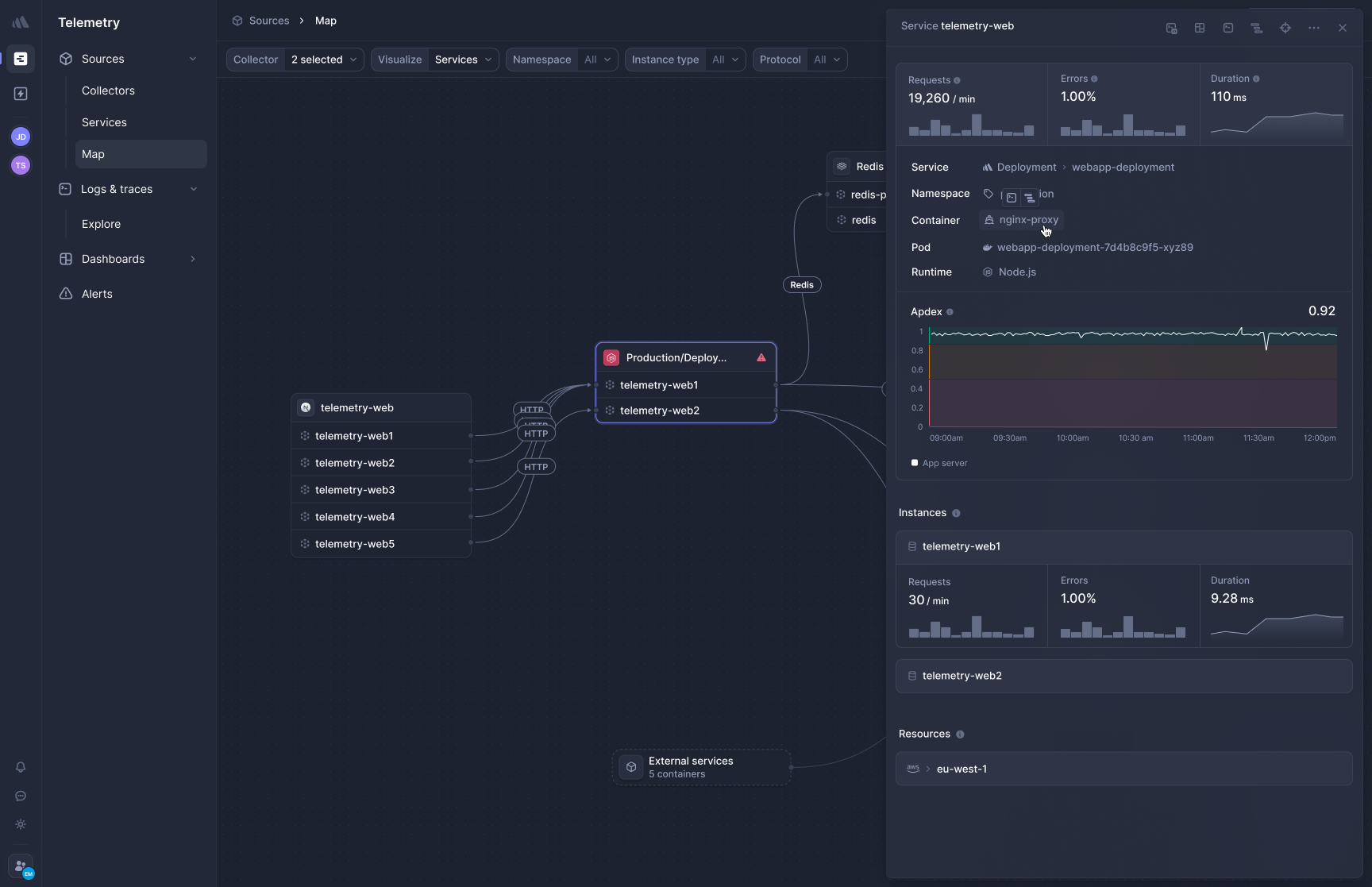
[Better Stack's APM](https://betterstack.com/tracing) captures traces at the kernel level. Deploy the collector once to your Kubernetes cluster, and HTTP/gRPC service calls, database queries (PostgreSQL, MySQL, Redis, MongoDB), and external API calls are traced automatically.
**Frontend-to-backend correlation** shows you what the user experienced in the browser alongside every service call and database query that happened as a result. A slow checkout becomes a trace that starts at the browser, flows through your API gateway, hits the payment service, and terminates at the database query that took 800ms. No product switching, no manual trace ID lookup.
**OpenTelemetry-native, zero lock-in.** All traces are stored in the OTel format. Your instrumentation belongs to you. If you ever migrate to a different backend, your traces move with you without a rewrite.
### Raygun: flamechart APM for server-side performance

Raygun APM instruments .NET, Ruby, and Node.js applications with language-specific agents. Once the agent is installed, you get the complete lifecycle of every HTTP request visualized as a flamechart: method calls, database queries, external API calls, and their timings, broken down by millisecond.
**Flamechart diagnostics** are where Raygun APM genuinely shines. The visual breakdown of a request's execution timeline, with method-level granularity and thread-level context for async operations, gives developers precise information about exactly where time is being spent. The integration with Crash Reporting means that if a performance issue causes an error, you can pivot from the APM trace directly to the error detail.
**Limitations to understand:** Raygun APM does not support distributed tracing across services in the OpenTelemetry sense. It traces individual service transactions, not the full request propagation chain across microservices. For polyglot environments (Python + Go + Node.js all talking to each other), the single-service flamechart provides less value than a distributed trace. Raygun also does not support eBPF-based zero-code instrumentation; agents must be installed and maintained per application.
Does your team maintain multiple services in different languages? That's the scenario where Better Stack's zero-code instrumentation removes real ongoing maintenance work.
| APM feature | Better Stack | Raygun |
|-------------|--------------|--------|
| **Instrumentation** | eBPF (zero code) | Agent per service |
| **Distributed Tracing** | Yes (full cross-service) | No (per-service only) |
| **OpenTelemetry** | Native | Not supported |
| **Flamechart/trace detail** | Span-level | Method-level (more granular) |
| **Database query tracing** | Automatic | Automatic (per agent) |
| **Frontend-to-backend** | Unified view | Requires RUM + APM both configured |
| **Language Support** | Any (eBPF) | .NET, Ruby, Node.js |
| **Pricing** | Included (trace GB) | $80-$800/mo per event tier |
## Real user monitoring
Both platforms offer RUM, and both measure Core Web Vitals, session data, and frontend errors. The comparison here comes down to integration depth: Raygun RUM is a standalone module that cross-references crash data; Better Stack RUM lives in the same data warehouse as your backend telemetry, logs, and traces.
### Better Stack: RUM inside unified observability

Better Stack RUM captures Core Web Vitals (LCP, CLS, INP), session replays, JavaScript errors, user flow analytics, and UTM/referrer attribution. Because it sits in the same warehouse as your backend data, a slow page load traced to your backend becomes a single investigation rather than two separate tools.
**Session replay** shows user interactions with controls for rage clicks, dead clicks, and errors. Playback skips dead time automatically. Sensitive fields are excluded at the SDK level.
**Website analytics** tracks referrers, UTM campaigns, entry/exit pages, locales, and real-time traffic sources. A traffic spike from a product launch on Hacker News correlates directly with backend load metrics in the same interface.
**Pricing:** $0.00150/session replay, included in the same billing model as logs and metrics. For 5M web events and 50,000 session replays, Better Stack costs approximately $102/month.
### Raygun: strong RUM with .NET ecosystem integration

Raygun RUM monitors page load performance, Core Web Vitals, XHR/Fetch timings, and user journeys. Its strength is the cross-reference with Crash Reporting: if a JavaScript error occurs during a user session, you can correlate the RUM session with the crash report to see exactly what the user was doing and what broke.
**Custom timings** let you instrument specific interactions (e.g., search bar response time, checkout step latency) without tracking everything by default. This is useful for performance budgets on specific user flows.
**APM + RUM correlation** connects frontend session data with backend server traces when both products are configured, giving you the same frontend-to-backend picture that Better Stack provides natively. The difference is that Better Stack's version requires no explicit correlation configuration; it happens automatically because the data lives in the same place.
**No session replay:** Raygun RUM does not currently include session replay functionality. For teams where watching user sessions is part of the debugging workflow, this is a meaningful gap.
| RUM feature | Better Stack | Raygun |
|-------------|--------------|--------|
| **Core Web Vitals** | Yes (LCP, CLS, INP) | Yes |
| **Session Replay** | Yes | No |
| **Frontend-to-backend** | Unified (automatic) | Requires APM + RUM both configured |
| **Website Analytics** | Yes (UTM, referrers, real-time) | Limited |
| **Custom Timings** | Yes | Yes |
| **JavaScript error correlation** | Automatic (same platform) | Cross-reference with Crash Reporting |
| **Log correlation** | Automatic | Not available |
| **Pricing** | ~$102/mo (5M events + 50K replays) | ~$160/mo (200K sessions, no replay) |
## AI features and MCP
Both platforms now have MCP servers and AI debugging workflows, though the design philosophy differs meaningfully.
### Better Stack: AI SRE and MCP server
**AI SRE** is an autonomous on-call engineer that activates during incidents. It analyzes your service map, queries recent logs, reviews deployment history, and surfaces probable root causes without waiting for you to start asking questions. At 3am, you're starting from a hypothesis rather than a blank slate.
**[Better Stack MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/)** connects Claude, Cursor, and any MCP-compatible client directly to your observability stack. Your AI assistant can query logs with ClickHouse SQL, check who's on-call, acknowledge incidents, and build dashboard charts through natural language.
```json
{
"mcpServers": {
"betterstack": {
"type": "http",
"url": "https://mcp.betterstack.com"
}
}
}
```
The MCP server covers uptime monitoring, incident management, log querying, metrics, dashboards, error tracking, and on-call scheduling.
### Raygun: AI Error Resolution and remote MCP

**AI Error Resolution** is Raygun's AI debugging integration. When you open an error group, Raygun assembles a prompt from the stack trace, environment data, and code context, then submits it to OpenAI or Azure OpenAI using your own API key. You get suggested resolutions within the error detail view, alongside conversation history so multiple engineers can discuss the same error. Importantly, no customer data is used for model training.
**Raygun MCP server** launched in a remote-first rebuilt version in October 2025. It gives AI tools direct access to your crash and RUM data: list error groups, retrieve instance details, update error statuses, track deployments, manage source maps, and analyze session performance metrics. The remote-first architecture means no local execution required, and updates happen centrally.
```json
{
"mcpServers": {
"Raygun": {
"url": "https://api.raygun.com/v3/mcp",
"headers": {
"Authorization": "Bearer YOUR_PAT_TOKEN"
}
}
}
}
```
The key distinction: Raygun's AI features are centered on error diagnosis. Better Stack's AI extends into full incident lifecycle (autonomous investigation, log querying, on-call management). Which is more useful depends on whether your AI needs access to error details specifically, or to your entire observability dataset.
| AI and MCP capability | Better Stack | Raygun |
|----------------------|--------------|--------|
| **AI SRE (autonomous)** | Yes | No |
| **AI Error Resolution** | Claude Code + Cursor prompts | Yes (OpenAI/Azure via your API key) |
| **MCP Server** | Yes, GA | Yes, GA (remote, Oct 2025) |
| **MCP data scope** | Logs, metrics, traces, incidents, on-call | Crash reports, RUM, deployments, source maps |
| **Natural language log queries** | Yes (via MCP) | No (crash data only) |
| **AI incident investigation** | Autonomous | Not included |
## Log management
This is where the comparison becomes straightforward. Better Stack includes full log management as a core product feature. Raygun does not include log management at all.
### Better Stack: all logs, always searchable
[Better Stack logs](https://betterstack.com/logs) ingests, indexes, and makes 100% of your logs searchable immediately. No tiered indexing, no choosing which logs to retain in hot storage. The query interface is SQL:
```sql
SELECT
service_name,
COUNT(*) as error_count,
AVG(duration_ms) as avg_duration
FROM logs
WHERE level = 'error'
AND timestamp > NOW() - INTERVAL '1 hour'
GROUP BY service_name
ORDER BY error_count DESC
```
Watch how Live Tail streams logs in real time with powerful filtering:
**Pricing:** $0.10/GB ingestion + $0.05/GB/month retention. A service producing 100GB/month costs $15 total.
### Raygun: no log management
Raygun does not include centralized log management. If you need to query application logs, investigate log-level context around an error, or monitor log-based anomalies, you'll need a separate tool. Common additions include Papertrail, Loggly, Datadog Logs, or Grafana Loki.
This isn't a criticism of Raygun's design philosophy; it's an accurate description of scope. Raygun is focused on error and performance diagnostics. If those are your only requirements, the absence of log management may not matter. If an incident response workflow requires log context, you're paying for it twice: once for whatever log tool you add, and once for the coordination overhead between systems.
| Log management | Better Stack | Raygun |
|----------------|--------------|--------|
| **Included** | Yes | No |
| **Query language** | SQL + PromQL | N/A |
| **Searchability** | 100% of ingested data | N/A |
| **Trace correlation** | Automatic | N/A |
| **Live tail** | Yes | N/A |
| **Pricing** | $0.10/GB ingestion | Separate tool required |
## Infrastructure monitoring
Same picture as log management: Better Stack includes it natively; Raygun doesn't.
### Better Stack: Prometheus-compatible metrics, no cardinality penalties
[Better Stack metrics](https://betterstack.com/infrastructure-monitoring) support full PromQL queries and work natively with existing Prometheus exporters. Cardinality has no pricing impact; costs are based on storage volume regardless of how many unique tag combinations your metrics generate.
Drag-and-drop dashboards let teams without PromQL expertise build visual charts, and SQL-based metric charts are available for teams that prefer code over configuration:
### Raygun: no infrastructure metrics
Raygun monitors application behavior (errors, traces, user sessions). It does not collect host metrics, container metrics, Kubernetes resource utilization, or any infrastructure-layer telemetry. For teams that need to correlate application errors with host-level resource exhaustion (CPU saturation causing latency, memory pressure causing crashes), that context requires a separate monitoring tool.
| Infrastructure monitoring | Better Stack | Raygun |
|--------------------------|--------------|--------|
| **Included** | Yes | No |
| **PromQL support** | Yes | N/A |
| **Cardinality penalties** | None | N/A |
| **Kubernetes monitoring** | Yes | No |
| **Docker monitoring** | Yes | No |
| **OTel metrics** | Native | N/A |
## Incident management
Better Stack includes incident management as a core platform feature. Raygun does not include on-call management, escalation policies, phone/SMS alerting, or incident response tooling.
### Better Stack: built-in on-call and incident lifecycle
[Better Stack incident management](https://betterstack.com/incident-management) includes on-call scheduling, escalation policies, unlimited phone and SMS alerts, and automatic post-mortem generation at $29/month per responder, with no additional tools required.
Incidents create dedicated Slack channels with investigation tools built in. Post-mortems are generated automatically from incident timelines. Advanced escalation policies support multi-tier workflows with time-based rules and metadata filters:
### Raygun: no incident management
Raygun sends alerts via email, Slack, Microsoft Teams, and webhooks when errors occur or performance thresholds are breached. It does not include on-call scheduling, escalation policies, phone/SMS delivery, or structured incident response workflows. Teams using Raygun for error alerting typically pair it with PagerDuty ($49-83/user/month) or OpsGenie for on-call management.
| Incident management | Better Stack | Raygun |
|--------------------|--------------|--------|
| **Included** | Yes | No |
| **Phone/SMS alerts** | Unlimited ($29/responder) | Requires PagerDuty/OpsGenie |
| **On-call scheduling** | Built-in | External |
| **Escalation policies** | Multi-tier, built-in | External |
| **Post-mortems** | Automatic | External |
| **Slack native incidents** | Yes | Alerts only |
| **Cost (5 responders)** | $145/month | $245-415/month (external tool) |
## Deployment and integration
### Better Stack
Better Stack deploys via a single Helm chart to Kubernetes. The eBPF collector runs as a DaemonSet, discovering services automatically. For OpenTelemetry users, the native OTel integration accepts telemetry directly:
Better Stack connects to 100+ integrations covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more. For log shipping, Vector integrates natively for processing pipelines before ingestion:
### Raygun
Raygun deploys via lightweight language SDKs. The installation pattern is typically "add the package, set the API key, run." Two lines of code for most languages, which users consistently describe as fast. The Raygun CLI (released February 2025) integrates error tracking into CI/CD pipelines for deployment correlation.
Raygun supports virtually every major language: JavaScript, TypeScript, .NET (C#, VB.NET, F#), Ruby, Python, Java, Go, PHP, Elixir, Node.js, Swift (iOS), Kotlin/Java (Android), Flutter, React Native, and Xamarin. Integration breadth across mobile frameworks is a genuine strength.
Third-party integrations include Slack, Microsoft Teams, GitHub, Jira, Bitbucket, Azure DevOps, PagerDuty, and email. Marketplaces include Shopify, Azure Marketplace, and Heroku Add-ons.
| Deployment | Better Stack | Raygun |
|------------|--------------|--------|
| **Setup method** | Helm chart (K8s) or SDK | SDK per application |
| **Time to first data** | Minutes (eBPF auto-discovery) | Minutes (2-line SDK) |
| **Code changes required** | Zero (eBPF) or minimal (OTel) | Per-application SDK install |
| **OpenTelemetry** | Native | Not supported |
| **Mobile SDK breadth** | Good | Excellent (Flutter, Xamarin, etc.) |
| **CI/CD integration** | Yes | Yes (CLI, Feb 2025) |
| **Shopify integration** | No | Yes |
## User experience and interface
Raygun's interface is purpose-built for error investigation. You land in a filtered list of error groups, sorted by frequency, recency, or user impact. Clicking through gives you full diagnostic context immediately. The navigation is shallow; you don't need to know which product you're in to find what you're looking for.
Better Stack's interface unifies all telemetry in one place. The navigation reflects the platform's breadth: Logs, Metrics, Traces, Errors, Incidents, Status Pages, all accessible from one sidebar. The trade-off is that more capabilities means more navigation, though the SQL query language makes cross-product investigation faster once you know it.
Both platforms allow saving query presets for frequently used views. Better Stack's Live Tail customization and preset system reduces repetitive setup:
Raygun's G2 and Capterra reviews frequently praise setup speed and diagnostic clarity, while noting the filtering interface for large error volumes can be limiting. The interface shows some age compared to newer tooling aesthetics, though it doesn't affect core functionality.
| UX aspect | Better Stack | Raygun |
|-----------|--------------|--------|
| **Query language** | SQL + PromQL | Custom per product |
| **Onboarding time** | Hours | Minutes to hours |
| **Investigation depth** | All telemetry in one view | Error/performance focused |
| **Mobile app** | No | No |
| **Preset/saved views** | Yes | Yes |
| **G2 rating** | High | 4.4+ (strong for APM/crash) |
## Status pages
### Better Stack: built-in, multi-channel
[Better Stack Status Pages](https://betterstack.com/status-pages) syncs automatically with incident management. When an incident is declared, the status page updates. Subscriber notifications go out via email, SMS, Slack, and webhook.
Features include custom branding, custom domains, password protection, SAML SSO for private pages, multi-language support, and scheduled maintenance announcements. Pricing: $12-208/month for advanced features, included with the platform at no additional licensing cost.
### Raygun: not included
Raygun does not include status page functionality. Teams that need external status communication will add Statuspage.io, Instatus, or a similar standalone product.
| Status pages | Better Stack | Raygun |
|--------------|--------------|--------|
| **Included** | Yes | No |
| **Incident sync** | Automatic | N/A |
| **Subscriber channels** | Email, SMS, Slack, webhook | N/A |
| **Custom branding** | Full CSS control | N/A |
| **Pricing** | $12-208/month | Separate tool required |
## Enterprise readiness
Raygun's compliance story is strong, and notably includes HIPAA. This distinguishes it from Better Stack in healthcare contexts.
### Raygun: HIPAA-compliant, solid enterprise features
Raygun is HIPAA compliant and willing to sign a Business Associate Agreement (BAA). This makes it usable for healthcare applications handling electronic Protected Health Information. The platform is also GDPR, CCPA, and PCI compliant.
Enterprise features include SAML SSO (available from the Business plan, or as an add-on on lower tiers), dedicated account managers from the Business plan, custom data retention policies, private Slack channel support at the Enterprise level, custom SLAs, and audit logs across all plans.
No SCIM provisioning is documented in the current feature set, which may be a gap for larger organizations managing user access at scale.
### Better Stack: strong enterprise baseline, no HIPAA
Better Stack's enterprise package covers the compliance and access control requirements most teams encounter: SOC 2 Type II, GDPR, SSO via Okta/Azure/Google, SCIM provisioning, RBAC, audit logs, and data residency options (EU + US regions, plus optional self-hosted S3 bucket). Enterprise customers get a dedicated Slack support channel and named account manager.
HIPAA is not supported. If you're in healthcare and need error monitoring for an application handling PHI, Raygun is the better-positioned option of these two.
| Enterprise feature | Better Stack | Raygun |
|-------------------|--------------|--------|
| **SOC 2 Type II** | ✓ | ✓ |
| **GDPR** | ✓ | ✓ |
| **HIPAA** | ✗ | ✓ (BAA available) |
| **CCPA** | ✓ | ✓ |
| **PCI** | ✗ | ✓ |
| **SSO (SAML/OIDC)** | ✓ | ✓ (Business plan+) |
| **SCIM Provisioning** | ✓ | Not documented |
| **RBAC** | ✓ | ✓ (user roles) |
| **Audit Logs** | ✓ | ✓ (all plans) |
| **Data Residency** | EU + US, optional S3 | Hosted only |
| **Dedicated Slack support** | Enterprise | Enterprise |
| **SLA** | Enterprise | Enterprise |
| **Named account manager** | Enterprise | Business+ |
## Final thoughts
These two products aren't really competing for the same buyer. **Raygun is a crash reporter that does its job well. Better Stack is an observability platform.** Comparing them directly is a bit like asking whether you'd rather have a really good kitchen knife or a full set of cookware.
If crash diagnostics is genuinely all you need, especially on .NET, Flutter, or mobile, Raygun is hard to beat. **The flamechart APM, the HIPAA BAA, and the code-level error detail view are all legitimately good.** If your monitoring conversation starts and ends with "why did this crash and whose code caused it," Raygun answers that question better than most tools at any price point.
That said, most teams don't stay in that narrow lane for long. At some point you need logs, or infrastructure metrics, or someone needs to be paged at 3am, and suddenly **you're paying for three more tools that don't share context with each other.**
That's where Better Stack changes the calculation. Instead of four separate invoices, you get **eBPF auto-instrumentation, SQL-queryable logs, OpenTelemetry-native traces, incident management with phone alerts, and status pages, all in one platform, connected without configuration.** Your AI assistant can query all of it through a single MCP connection.
The gap between the two platforms isn't really about features. It's about scope. **Raygun's diagnostic depth for pure crash analysis is real**, and Better Stack doesn't pretend otherwise. But most teams asking "should I use Raygun" are actually asking **"how do I get visibility into my production systems"**, and that's a much broader question than Raygun is built to answer.
If the broader question is what brought you here, [start your Better Stack free trial](https://betterstack.com) and see how much of your current tool stack it replaces.!