# Better Stack vs Middleware: A Complete Comparison for 2026
The observability market has a crowded middle tier, and Middleware is one of the newer entrants shaping it. Launched out of Y Combinator in 2023, it focuses on **unified telemetry, OpenTelemetry-native collection, and simple per-GB pricing**, avoiding the per-host cost traps common in older platforms. For teams moving away from tools like Datadog, that pitch is compelling.
At a glance, Middleware and Better Stack look similar. Both cover **infrastructure monitoring, APM, log management, RUM, alerting, and AI-assisted debugging**. Both rely on **OpenTelemetry** and **volume-based pricing**. On paper, they can seem interchangeable.
In practice, they are not.
The real differences show up in **incident management depth, status page support, MCP availability, log query capabilities, and how each platform approaches AI workflows**. These are the areas that shape day-to-day usage and long-term cost.
This comparison breaks down each category in detail, highlights where each platform leads, and ends with a clear recommendation based on real-world use cases.
## Quick comparison at a glance
| Category | Better Stack | Middleware |
|----------|-------------|------------|
| **Deployment** | eBPF auto-instrumentation | OTel-based agent, auto-instrumentation on Kubernetes |
| **Architecture** | Unified (logs, metrics, traces, RUM together) | Unified (logs, metrics, traces, RUM together) |
| **Query language** | SQL + PromQL | Custom query UI + PromQL |
| **Pricing model** | Data volume + responders + monitors | Per GB flat ($0.30/GB), RUM/synthetics add-ons |
| **OpenTelemetry** | Native, no premium charges | Native, OTel-based agents |
| **Incident management** | Built-in (on-call, escalation, phone/SMS) | Alerting only, no on-call scheduling |
| **Status pages** | Built-in, multi-channel | Built-in (added in 2024 update) |
| **AI features** | AI SRE (incident investigation), MCP server (GA) | OpsAI (auto-detect + auto-fix + PR generation) |
| **LLM observability** | Via integrations | Dedicated LLM Observability product |
| **Enterprise compliance** | SOC 2 Type II, GDPR, SSO, SCIM, RBAC, audit logs | SOC 2 Type II, GDPR, HIPAA |
| **Integrations** | 100+ covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more | OTel-native, Prometheus, Kubernetes, AWS, GCP, Azure, Vercel |
## Platform architecture
Both platforms converge on the same architectural thesis: one agent, one storage layer, one interface. The main architectural divergence is at the collection layer. Better Stack uses eBPF, which operates at the kernel level without touching application code. Middleware uses an OpenTelemetry-based agent that requires installation per service but ships with auto-instrumentation for Kubernetes deployments.
### Better Stack: eBPF collection, unified storage
Better Stack's architecture is built around a kernel-level eBPF collector that captures traces, logs, and metrics without application code changes. Deploying to Kubernetes means the collector runs as a DaemonSet, discovers services automatically, instruments database calls, and starts producing distributed traces before you write a single configuration line.
**Unified storage** treats logs, metrics, and traces as wide events in the same warehouse. SQL and PromQL work across all signal types, so you are not switching query languages when you switch from a log investigation to a metrics chart. When an alert fires, service maps, related logs, metric anomalies, and trace examples appear in one view.

### Middleware: OTel-native, agent-based collection
Middleware's collector is built on OpenTelemetry. The agent instruments applications and ships telemetry to Middleware's backend. On Kubernetes, Middleware supports auto-instrumentation through a Helm chart that deploys the kube-agent and enables APM for supported languages automatically. Outside Kubernetes, teams install the APM agent per service and the JavaScript snippet for RUM.

Middleware also ships an observability pipeline, a data preprocessing layer that lets you drop, sample, or redact telemetry before it reaches storage. Drop debug logs from staging environments, mask PII at ingestion, normalize inconsistent field names across services. This is a practical cost-control feature that Better Stack does not offer in the same form. Is your team paying to store health check logs that no engineer has ever opened? Middleware's pipeline rules let you drop them before they hit your bill.
| Architecture aspect | Better Stack | Middleware |
|---------------------|--------------|------------|
| **Data collection** | eBPF (kernel-level, zero code) | OTel agent (auto-instrumentation on K8s) |
| **Storage model** | Unified warehouse | Unified timeline |
| **Query language** | SQL + PromQL (universal) | Custom UI + PromQL |
| **Data pipeline** | No preprocessing layer | Ingestion control with drop/sample rules |
| **Time to first insights** | Minutes (zero code required) | Minutes on K8s, hours for manual agent installs |
| **OpenTelemetry support** | First-class native | First-class native |
| **Data portability** | Full (OTel format, optional S3 export) | OTel format |
## Pricing comparison
Both platforms use volume-based pricing, which already puts them in a different category from Datadog's per-host model. The differences are in what that volume rate includes, how add-on products are priced, and what the combined cost looks like at scale.
### Better Stack: volume plus responders
Better Stack charges for data ingestion, storage, responders, and monitors. There are no cardinality penalties, no per-host fees, and no indexing tiers. Every ingested log is searchable immediately without paying a separate indexing fee.
**Published pricing:**
- Logs: $0.10/GB ingestion + $0.05/GB/month retention (100% searchable)
- Traces: $0.10/GB ingestion + $0.05/GB/month retention
- Metrics: $0.50/GB/month (no cardinality penalties)
- Error tracking: $0.000050 per exception
- Responders: $29/month (unlimited phone/SMS)
- Monitors: $0.21/month each
**100-host deployment example:** $791/month
- Telemetry (2.5TB/month): $375
- 5 Responders: $145
- 100 Monitors: $21
- Error tracking (5M exceptions): $250
### Middleware: flat per-GB with add-ons
Middleware's published pricing is simpler at the top level: $0.30/GB for the combined volume of metrics, logs, and traces. RUM sessions, synthetic checks, and browser test runs are billed separately. OpsAI (root cause analysis and auto-fix) is token-based; error detection itself is free.
**Published pricing:**
- Data volume: $0.30/GB (metrics, logs, traces combined)
- RUM sessions: $1 per 1,000 sessions
- Synthetic checks: $1 per 5,000 checks
- Browser test runs: $10 per 1,000 runs
- OpsAI: contact sales for token-based pricing (error detection is free)
- Default retention: 30 days on Pay-as-you-go
**100-host deployment example (100GB/day = ~3TB/month):** approximately $900/month
- Data volume (3TB): $900
- RUM (50,000 sessions): $50
- Synthetic (20,000 checks): $4
- OpsAI tokens: variable (contact sales)
The flat rate looks cleaner, but the per-GB figure ($0.30) is higher than Better Stack's blended equivalent when you account for separate ingestion and storage charges across signal types. For a team running 2.5TB/month, Middleware's data volume line alone is $750 before RUM, synthetics, and OpsAI. Better Stack's equivalent data cost is $375.
**What Middleware does better on pricing: the observability pipeline.** If you can drop 30% of your data before it hits storage via Middleware's pipeline rules, the effective rate changes substantially. Teams that invest in configuring drop rules can achieve real savings. Better Stack's pricing advantage is consistent without that overhead.
### 3-year TCO comparison (100-host deployment)
| Category | Better Stack | Middleware |
|----------|-------------|------------|
| Platform (logs, metrics, traces) | $33,600 | $54,000 |
| RUM | $3,672 | $1,800 |
| Error tracking | $9,000 | Included (detection free) |
| Incident management | $5,220 | Not included (requires PagerDuty or similar) |
| Status pages | Included | Included |
| Engineering overhead | Minimal | Pipeline configuration overhead |
| **Estimated total** | **~$51,500** | **~$65,000+ (excl. on-call tooling)** |
*Estimates based on published rates and typical usage patterns. Middleware's OpsAI token costs excluded as pricing is not publicly disclosed.*
The gap widens when you add on-call tooling. Middleware's alerting does not include on-call scheduling, escalation policies, or phone/SMS delivery. Teams running Middleware typically integrate PagerDuty or OpsGenie on top, which adds $245-415/month for five responders. Better Stack includes all of that at $29/responder/month.
## APM
Both platforms instrument distributed traces, visualize service maps, and automatically detect database calls. The collection mechanism and lock-in implications differ.
### Better Stack: eBPF traces, zero lock-in
[Better Stack's APM](https://betterstack.com/tracing) captures distributed traces via eBPF without SDK installation. HTTP and gRPC traffic between services appears immediately after collector deployment. Database calls to PostgreSQL, MySQL, Redis, and MongoDB are traced automatically.
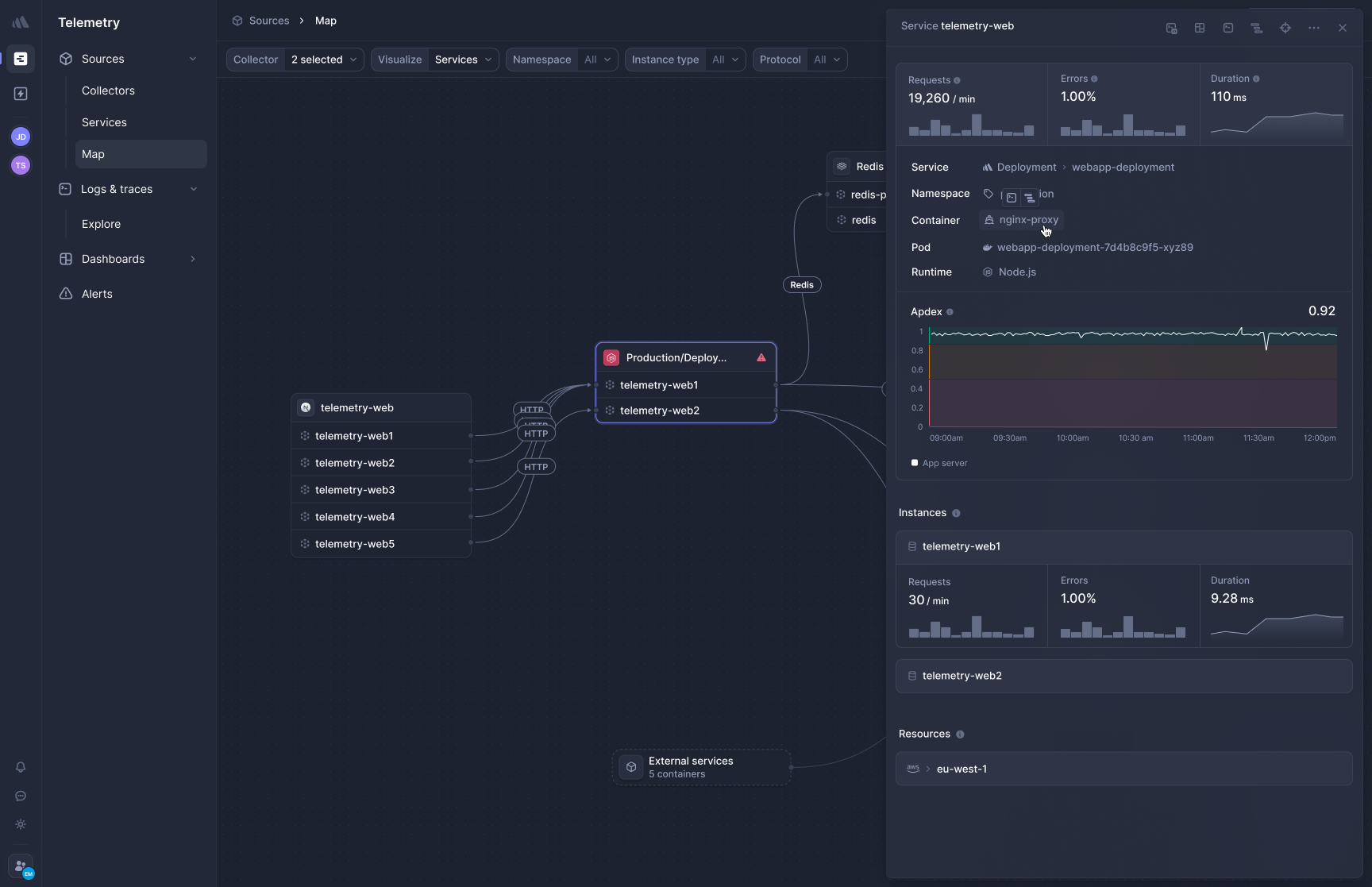
**Frontend-to-backend correlation** connects browser session data with backend traces in one view. When a page load is slow, you trace it from the initial request through every downstream service and database call without switching products.
**OpenTelemetry-native, zero lock-in.** Your traces use the OTel format natively. Sending traces elsewhere requires changing one configuration line, not your codebase. How much would it cost your engineering team to migrate off a proprietary agent today? That migration tax is what you avoid with Better Stack's OTel-first approach.
### Middleware: OTel APM with OpsAI integration
Middleware's APM uses OTel-based agents with auto-instrumentation on Kubernetes. Supported languages include Java, Node.js, Python, Go, Ruby, .NET, and PHP. Outside Kubernetes, teams install per-service agents and configure environment variables.

What sets Middleware's APM apart is its OpsAI integration. When an APM trace surfaces an error, OpsAI can automatically detect it, pull the relevant source files via GitHub's MCP server, perform root cause analysis, and open a pull request with a suggested fix. This goes beyond Better Stack's AI SRE, which investigates and hypothesizes but does not write code.
For teams where the bottleneck is code-level debugging rather than incident triage, OpsAI's auto-fix workflow is a meaningful differentiator. The question is whether you want automated code changes in production workflows, which some teams embrace and others treat with caution.
**APM downstream graphs** (added in Middleware's April 2025 update) show call volume and latency for every downstream dependency in a trace, making it easier to pinpoint which service in a chain is contributing latency.
| APM feature | Better Stack | Middleware |
|-------------|--------------|------------|
| **Instrumentation** | eBPF (zero code changes) | OTel agent (auto on K8s, manual otherwise) |
| **Database tracing** | Automatic (Postgres, MySQL, Redis, Mongo) | Automatic (Postgres, MySQL, Redis, Mongo + more) |
| **Frontend-to-backend** | Unified view, single interface | Unified timeline (RUM + APM) |
| **OpenTelemetry** | Native, no lock-in | Native, no lock-in |
| **AI debugging** | AI SRE hypothesizes root cause | OpsAI generates code fix + pull request |
| **Downstream graphs** | Service map view | Dedicated downstream APM graphs |
| **Code-level profiling** | Network-level only | Continuous profiling (Next.js, others) |
## Log monitoring
The log economics differ between these platforms despite both offering unified storage.
### Better Stack: 100% searchable, SQL queries
[Better Stack logs](https://betterstack.com/logs) treats every ingested log as immediately searchable. No indexing tier, no choosing which logs to make queryable. The same $0.10/GB ingestion applies whether you search those logs ten times or never.
SQL querying works across all log data:
```sql
SELECT
service_name,
COUNT(*) as error_count,
AVG(duration_ms) as avg_duration
FROM logs
WHERE level = 'error'
AND timestamp > NOW() - INTERVAL '1 hour'
GROUP BY service_name
ORDER BY error_count DESC
```
### Middleware: log patterns, pipeline filtering, OpsAI correlation
Middleware's log monitoring includes log patterns, a feature that automatically clusters similar log messages together and shows which services are emitting the same patterns. Instead of reading through hundreds of similar error lines, you see the pattern, its frequency, and its affected hosts at a glance. This is genuinely useful for noisy microservice environments where the signal is buried in repetition.

OpsAI correlates logs with traces to surface root cause hypotheses. When Middleware detects an error pattern in logs, OpsAI can attempt to link it to a trace, identify the affected code file, and propose a fix. The log-to-trace-to-fix workflow is more tightly integrated than any competitor at this price point.
What Middleware's log pricing does that Better Stack's does not is give you control over what you pay for. The observability pipeline lets you drop entire log categories before they hit storage. Teams paying $0.30/GB have a strong incentive to configure aggressive drop rules. Is your team logging every health check endpoint response? You are paying for every one of them on Middleware. Configure a drop rule and you are not.
| Log management | Better Stack | Middleware |
|----------------|--------------|------------|
| **Pricing model** | $0.10/GB ingestion + $0.05/GB storage | $0.30/GB (combined) |
| **Searchability** | 100% of ingested logs | 100% of stored logs |
| **Query language** | SQL + PromQL | Custom query UI + PromQL |
| **Log patterns** | No automatic clustering | Log pattern clustering |
| **Pipeline filtering** | No | Yes (drop/sample/redact before billing) |
| **OpsAI correlation** | No | Yes (log-to-trace-to-fix) |
| **Retention (default)** | Configurable | 30 days (pay-as-you-go) |
## Infrastructure monitoring
Both platforms cover hosts, containers, Kubernetes, cloud providers, and databases. The cardinality story is the same: neither penalizes you for high-cardinality tags.
### Better Stack: cardinality-free metrics
[Better Stack metrics](https://betterstack.com/infrastructure-monitoring) charges based on data volume only. Add tags freely, no cardinality anxiety. Prometheus-compatible with full PromQL support.
### Middleware: Kubernetes-native with enhanced dashboards
Middleware's infrastructure monitoring covers hosts, Kubernetes, containers, databases, serverless, and major cloud providers (AWS, GCP, Azure). Kubernetes dashboards received significant updates in the June 2025 release with enhanced visualizations for cluster health, pod status, and resource utilization.

Middleware's **database monitoring** product covers PostgreSQL, MySQL, Redis, MongoDB, and others with query-level performance data. Slow query visualization and connection pool metrics are available without additional configuration on supported databases.
**Continuous profiling** is available for Next.js and expanding to other runtimes. This shows CPU and memory allocation at the function level, which is useful for diagnosing performance regressions in high-traffic services. Better Stack does not have an equivalent continuous profiling product.
| Infrastructure feature | Better Stack | Middleware |
|-----------------------|--------------|------------|
| **Pricing model** | Volume-based | Volume-based (combined with logs/traces) |
| **Cardinality penalty** | None | None |
| **Kubernetes** | Full support | Enhanced dashboards (June 2025 update) |
| **Database monitoring** | Auto-traced (query-level) | Dedicated database monitoring product |
| **Continuous profiling** | No | Yes (Next.js, expanding) |
| **Cloud monitoring** | AWS, GCP, Azure via integrations | AWS, GCP, Azure (dedicated solutions pages) |
| **PromQL support** | Yes | Yes |
## Incident management
This is the clearest gap between the platforms. Middleware provides alerting. Better Stack provides a full incident management product. Those are not the same thing, and the difference is significant for on-call teams.
### Better Stack: end-to-end incident management
[Better Stack incident management](https://betterstack.com/incident-management) includes on-call scheduling, escalation policies, unlimited phone and SMS alerts, dedicated Slack incident channels, and automatic post-mortem generation. Everything from alert to resolution happens in one product.
At $29/responder/month with unlimited phone and SMS included, Better Stack covers the full on-call workflow without add-ons. Five responders cost $145/month. The same capability via PagerDuty costs $245-415/month on top of whatever observability platform you are already paying for.
### Middleware: alerting with on-call integrations
Middleware provides live alerting with real-time notifications, customizable aggregation rules, and integrations with communication tools including Slack, MS Teams, PagerDuty, OpsGenie, and Jira. The Middleware pricing page lists incident management as a feature, but it refers to alert management and on-call integrations, not a self-contained on-call scheduling system.
Middleware's alerting is genuinely capable: multi-condition rules, anomaly detection via OpsAI, and integration with your existing incident workflow. But if you need timezone-aware on-call rotations, escalation policies with time-based rules, automatic post-mortem generation, and phone call delivery without a third-party tool, you will need to add PagerDuty or OpsGenie alongside Middleware.
Are you currently paying for both an observability platform and a separate on-call tool? That combination describes a large portion of teams evaluating both Better Stack and Middleware.
| Incident feature | Better Stack | Middleware |
|------------------|--------------|------------|
| **On-call scheduling** | Built-in (rotation management, timezone-aware) | Via PagerDuty/OpsGenie integration |
| **Phone/SMS delivery** | Unlimited (included at $29/responder) | Via integration only |
| **Escalation policies** | Built-in (multi-tier, time-based) | Via integration only |
| **Incident channels** | Native Slack/Teams (dedicated per incident) | Slack/Teams notifications |
| **Post-mortem generation** | Automatic | No |
| **Monthly cost (5 responders)** | $145 | $0 (alerting) + PagerDuty ($245-415) |
## OpsAI and AI features
Both platforms have invested significantly in AI-native workflows, but the product philosophies are different. Better Stack built an AI SRE that investigates incidents autonomously and an MCP server that connects AI assistants directly to your observability data. Middleware built OpsAI, which goes further into the code layer: it detects issues, performs root cause analysis, and generates a pull request with a proposed fix.
### Better Stack: AI SRE and MCP server
**AI SRE** activates during incidents and analyzes your service map, recent deployments, log patterns, and metrics anomalies without manual prompting. At 3am, when an alert fires and you are still waking up, AI SRE delivers a hypothesis before you open a terminal.
**[Better Stack MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/)** is generally available to all customers. It connects Claude, Cursor, and any MCP-compatible AI assistant directly to your observability stack. Your AI assistant can run SQL queries against your logs, check who is on-call, acknowledge incidents, and build dashboard charts through natural language.
```json
{
"mcpServers": {
"betterstack": {
"type": "http",
"url": "https://mcp.betterstack.com"
}
}
}
```
The MCP server covers the full Better Stack surface: uptime monitoring, incident management, log querying, metrics, dashboards, error tracking, and on-call scheduling. You control what the AI assistant can access, allowlisting read-only tools or blocklisting destructive operations.
### Middleware: OpsAI auto-fix and GitHub PR generation
**OpsAI** is Middleware's most distinctive product. It monitors APM traces, RUM events, Kubernetes logs, and infrastructure metrics for errors and anomalies. When it detects a problem, it performs root cause analysis by pulling the relevant source files via GitHub's MCP server integration and generates a pull request with a proposed code fix.

The workflow is: detect error from APM/RUM, correlate with logs, access source files via GitHub MCP, identify the likely line causing the failure, propose a minimal code change, open a pull request for developer review. In early customer testing, OpsAI automatically resolved over 60% of production issues.
OpsAI operates on a token-based model. Error detection is free; root cause analysis and auto-fix consume tokens. Pricing for tokens is available on request. The distinction matters: teams need to model their expected token consumption before committing to OpsAI at scale.
What OpsAI does not do: it does not provide an MCP server for external AI assistants to query Middleware. The MCP integration in Middleware's architecture runs in one direction, from OpsAI to GitHub, not from Claude or Cursor into Middleware's data. If your workflow involves asking an AI assistant to query your logs or acknowledge incidents, Better Stack's MCP server covers that; Middleware does not have an equivalent today.
| AI feature | Better Stack | Middleware |
|------------|--------------|------------|
| **AI SRE / incident investigation** | Yes (autonomous, during incidents) | Yes (OpsAI detects and diagnoses) |
| **MCP server for AI assistants** | Yes (GA, all customers) | No |
| **Auto-fix + pull request generation** | No | Yes (OpsAI, token-based) |
| **Natural language log queries** | Via MCP in Claude/Cursor | No external MCP |
| **Anomaly detection** | Via AI SRE | OpsAI across APM, RUM, infra |
| **GitHub integration** | Via MCP | Built-in (OpsAI reads files via GitHub MCP) |
| **Pricing** | Included | Error detection free; RCA/fix tokens extra |
## Real user monitoring
Both platforms offer RUM with Core Web Vitals, session replay, and product analytics. The integration story differs.
### Better Stack: unified RUM

Better Stack RUM sits in the same data warehouse as backend telemetry. Frontend events and backend traces are queryable with the same SQL syntax in the same interface, with no configuration required to correlate them. Session replays link directly to JavaScript errors and backend distributed traces.
**Pricing:** $0.00150/session replay, included in the same volume-based billing model as logs and metrics.
For 50,000 session replays, Better Stack costs approximately $75, part of a combined platform bill with no separate RUM product to license.
### Middleware: RUM with mobile support
Middleware added RUM in mid-2024 and has iterated steadily since. Core Web Vitals (FCP, LCP, FID, CLS), session replay, and user interaction tracking are all available. Middleware's RUM roadmap explicitly includes native iOS and Android app support, which represents coverage Better Stack does not currently provide.

**Pricing:** $1 per 1,000 RUM sessions. For 50,000 sessions, that is $50/month. Session replay is not separately listed from session pricing, but browser test runs are charged separately at $10/1,000 runs.
Middleware's RUM connects to APM traces on the unified timeline, so a slow page load trace from the frontend carries through to the backend service that caused it. The integration works well in practice.
For teams building mobile apps, Middleware's stated roadmap to native iOS and Android RUM is a meaningful differentiator over Better Stack's current web-only coverage. If mobile RUM is a current requirement rather than a future one, verify Middleware's mobile SDK availability at evaluation time.
| RUM feature | Better Stack | Middleware |
|-------------|--------------|------------|
| **Session replay** | Yes ($0.00150/replay) | Included in session pricing |
| **Core Web Vitals** | LCP, CLS, INP | FCP, LCP, FID, CLS |
| **Frontend-to-backend** | Unified (same SQL interface) | Unified timeline |
| **Mobile RUM** | Web only (mobile not yet available) | iOS/Android on roadmap |
| **Product analytics** | Yes (auto-captured events, funnels) | Yes |
| **Session pricing** | Volume-based | $1 per 1,000 sessions |
## Synthetic monitoring and browser testing
Middleware has invested significantly in synthetic monitoring, treating it as a first-class product rather than an afterthought. Better Stack offers uptime monitoring and synthetic checks; Middleware adds dedicated browser testing with multi-step flows.
### Better Stack: uptime and synthetic checks
[Better Stack Status Pages](https://betterstack.com/status-pages) and uptime monitoring provide HTTP/HTTPS checks, SSL certificate monitoring, and multi-location synthetic tests. Checks run from multiple regions with configurable intervals.
### Middleware: synthetic monitoring plus browser testing
Middleware separates synthetic monitoring (API and endpoint checks) from browser testing (multi-step user flow simulation with a scriptable browser). Browser testing supports full interaction scripts: click a login button, fill a form, assert on the result, screenshot the page. This goes beyond availability checks into functional test coverage.

**Pricing:** Synthetic checks at $1/5,000 checks; browser test runs at $10/1,000 runs. The pricing is explicit and calculable up front, which is better than the opaque pricing common in this category.
For teams that want to simulate full user journeys (not just ping endpoints) as part of their observability stack, Middleware's browser testing product is a genuine advantage over Better Stack's current capabilities.
| Synthetic / browser testing | Better Stack | Middleware |
|----------------------------|--------------|------------|
| **HTTP/HTTPS checks** | Yes | Yes |
| **Multi-step browser flows** | No | Yes (Browser Testing product) |
| **Screenshot on failure** | No | Yes |
| **SSL monitoring** | Yes | Yes |
| **Pricing** | Included in platform | $1/5K checks + $10/1K browser runs |
## LLM observability
Middleware ships a dedicated LLM Observability product that tracks token usage, model latency, error rates, and cost per model call. As teams deploy AI-powered features, understanding which LLM calls are expensive, slow, or failing becomes a real operational concern. Middleware treats this as a first-class observability signal.

Better Stack does not have a dedicated LLM observability product. Teams monitoring LLM costs and latency with Better Stack would need to instrument application code to emit those metrics as custom events and query them via SQL. That works, but it requires more setup than Middleware's out-of-the-box LLM monitoring.
For teams shipping AI-powered products, Middleware's LLM observability product is worth evaluating as a differentiator. Is LLM cost and latency visibility a current operational need for your team, or a future consideration? That timing matters for the evaluation.
| LLM observability | Better Stack | Middleware |
|-------------------|--------------|------------|
| **Dedicated product** | No | Yes |
| **Token usage tracking** | Via custom events | Built-in |
| **Model latency monitoring** | Via custom metrics | Built-in |
| **Cost per model call** | Via custom events | Built-in |
## Status pages
Both platforms now include status pages. Middleware added status pages in early 2024 as part of a broader platform update. Better Stack's status pages have been a core product for longer and offer more notification channels.
### Better Stack: multi-channel status pages
[Better Stack Status Pages](https://betterstack.com/status-pages) include subscriber notifications via email, SMS, Slack, and webhooks. Status pages sync automatically with incident management, so when an incident is declared, the status page updates without manual intervention. Custom domains, password protection, SAML SSO for private pages, and full CSS customization are included.
**Pricing:** $12-208/month for advanced features, included at no additional platform cost with Better Stack's incident management.
### Middleware: status pages with Slack and email notifications
Middleware's status pages support public-facing status with incident updates, scheduled maintenance windows, and subscriber notifications via Slack and email. Synthetic checks feed directly into status page uptime indicators. The feature set covers the core requirements, though SMS notifications and webhook subscriptions that Better Stack offers are not listed as available in Middleware's implementation.

| Status pages | Better Stack | Middleware |
|--------------|--------------|------------|
| **Subscriber notifications** | Email, SMS, Slack, webhook | Slack and email |
| **Incident sync** | Automatic | Yes |
| **Custom domains** | Yes | Yes |
| **Custom branding/CSS** | Full customization | Yes |
| **Private pages (SSO/password)** | Yes | Not documented |
| **Pricing** | $12-208/month (transparent) | Included in platform |
## Enterprise readiness
Both platforms clear the baseline requirements that most enterprise procurement processes require. The differences are in compliance coverage scope and the specific support model.
Better Stack offers SOC 2 Type II, GDPR, SSO via Okta/Azure/Google, SCIM provisioning, RBAC, audit logs, EU and US data residency, optional S3 bucket for self-hosted data, a dedicated Slack support channel, and a named account manager.
Middleware lists HIPAA compliance alongside SOC 2 Type II and GDPR, which is a meaningful differentiation for healthcare and regulated industries. Middleware also offers "Bring Your Own Cloud" on enterprise contracts, a dedicated account team, multi-year contract discounts, custom data retention, and 24/7 support.
The compliance difference is notable. If your organization needs HIPAA compliance without running a separate compliant data store, Middleware clears that bar and Better Stack currently does not. For teams outside regulated industries, the enterprise feature sets are comparable.
| Enterprise feature | Better Stack | Middleware |
|-------------------|--------------|------------|
| **SOC 2 Type II** | Yes | Yes |
| **GDPR** | Yes | Yes |
| **HIPAA** | No | Yes |
| **SSO (SAML/OIDC)** | Yes (Okta, Azure, Google) | Yes |
| **SCIM provisioning** | Yes | Not publicly documented |
| **RBAC** | Yes | Yes |
| **Audit logs** | Yes | Yes |
| **Data residency** | EU + US, optional S3 | Bring Your Own Cloud |
| **Dedicated Slack support** | Yes | Yes (Dedicated Slack/MS Teams Channel) |
| **Named account manager** | Yes | Yes (Dedicated Account Team) |
| **24/7 support** | Enterprise SLA | Yes (enterprise) |
| **FedRAMP** | No | No |
## Final thoughts
Better Stack and Middleware are solving a similar problem for a similar audience. Both are **OpenTelemetry-native, volume-priced, and far more cost-efficient than legacy platforms** like Datadog or Dynatrace for teams that do not need enterprise SIEM or FedRAMP compliance.
The difference shows up in **where each platform goes deeper**.
If your priority is **running the full incident lifecycle in one place**, **Better Stack is the more complete option**. It includes **on-call scheduling, escalation policies, alert delivery, post-mortems, and AI-assisted investigation** without requiring additional tools. The **eBPF collector removes instrumentation overhead**, and the **MCP server connects your observability data directly to AI tools** your engineers already use.
å
The honest takeaway is simple. **Better Stack is the more complete and cost-efficient platform for managing incidents end to end**, especially when you factor in the cost of external on-call tooling. **Middleware stands out in specialized areas like auto-fix workflows and AI/LLM observability**.
Neither is the wrong choice. It comes down to **which gaps matter most for your team right now**.
You can try Better Stack here: [https://betterstack.com](https://betterstack.com)