# Better Stack vs Lumigo: A Complete Comparison for 2026
Most tracing tools tell you a Lambda call to SQS failed. Lumigo shows you the message body that caused it. That payload-level visibility, captured without code changes, is what made Lumigo the default choice for serverless teams debugging event-driven AWS architectures.
There is, however, a complication worth addressing before you read any further. **In February 2026, Dash0 acquired Lumigo. The platform will remain operational until at least the end of 2026, after which all customers are expected to migrate to Dash0.** If you are evaluating Lumigo today, you are not evaluating a stable long-term vendor. You are evaluating a platform on a known sunset timeline.
**Better Stack covers the same observability ground as Lumigo** (tracing, log management, infrastructure metrics, incident management, and AI-powered investigation) **without an acquisition-driven migration risk.** It uses eBPF-based zero-code instrumentation across Kubernetes, Docker, and AWS environments, a unified query layer (SQL and PromQL), and predictable volume-based pricing. Lumigo's payload-capture approach is genuinely strong in pure Lambda environments, but its future belongs to Dash0, not to Lumigo itself.
This article covers both honestly: where Lumigo excels, where Better Stack has the edge, and what the acquisition means for anyone seriously evaluating their options.
## Quick comparison at a glance
| Category | Better Stack | Lumigo |
|----------|-------------|--------|
| **Deployment** | Minutes (eBPF, Helm, zero code) | Minutes for Lambda; container support more limited |
| **Architecture** | Unified (logs, metrics, traces, incidents) | Trace-first; logs and metrics are add-ons |
| **AWS Lambda support** | Yes (OpenTelemetry-based) | Best-in-class (payload-level visibility) |
| **Kubernetes support** | First-class (eBPF DaemonSet) | Improving; historically Lambda-focused |
| **Query language** | SQL + PromQL (unified) | Proprietary interface; limited SQL |
| **Pricing model** | Data volume + responders | Trace count + log volume (tiered) |
| **OpenTelemetry** | Native, no lock-in | Supported; own tracers preferred |
| **Incident management** | Built-in (on-call, escalations, status pages) | Not included; external tools required |
| **AI features** | AI SRE + MCP server (GA) | Lumigo Copilot (RCA, alerts) |
| **Platform future** | Independent, funded, growing | Being sunset into Dash0 by end of 2026 |
| **Integrations** | 100+ covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more | 50+ AWS and cloud-native integrations |
## Platform architecture and future
The most important architectural question about Lumigo in 2026 is not about its data model. It is about organizational continuity. Dash0 acquired Lumigo in February 2026, and has confirmed the Lumigo platform will be sunset by the end of 2026, with all customers migrating to Dash0. New signups on lumigo.io are already redirected to Dash0. If you choose Lumigo today, you are committing to a forced migration within months, not a vendor relationship you can rely on long-term.
That is worth stating plainly, because no amount of feature-level comparison changes the underlying situation. Evaluating Lumigo vs Better Stack is partly a question of: do you want a stable, independent platform or one that requires a migration within your contract period?
### Better Stack: unified architecture built to scale
Better Stack's architecture rests on three foundations: eBPF-based auto-instrumentation, OpenTelemetry-native data collection, and a unified storage layer that treats logs, metrics, and traces as wide events queryable with the same SQL or PromQL syntax.
Deploy the collector to Kubernetes via a single Helm chart, and it runs as a DaemonSet across nodes, automatically discovering services and capturing HTTP/gRPC traffic, database queries (PostgreSQL, MySQL, Redis, MongoDB), and infrastructure metrics without any application code changes. Here is how the collector works at a high level:
One interface shows service maps, logs, metrics, and traces together. No product-switching during incidents. When an alert fires, all relevant context is in a single view: which services are affected, what the recent log output shows, and what the distributed trace looks like across the call chain.

**OpenTelemetry-native from day one.** Better Stack does not bolt OTel support on top of a proprietary pipeline. Telemetry flows through the OTel format natively, which means your data is portable. You could switch backends by changing a configuration line, not your codebase.
### Lumigo: trace-first, AWS-centric, transitioning
Lumigo's architecture was designed around a specific insight: AWS managed services (Lambda, SQS, EventBridge, DynamoDB, API Gateway) are opaque by default. Lumigo's instrumentation layer intercepts outbound requests and captures the full request and response payloads, not just span metadata. When a Lambda function calls SQS and something goes wrong, you see exactly what message was published and what the response contained. That level of payload visibility is a genuine differentiator in pure Lambda environments.

The architectural limitation is scope. Lumigo was built for Lambda and serverless first. Kubernetes observability, infrastructure metrics, and log management were added later and, per G2 reviews, container tracing capabilities have historically lagged behind the Lambda experience. Lumigo's log management is positioned as complementary to traces, not as a standalone product.
More critically: Lumigo's architecture is in transition. Dash0's FAQ confirms the Lumigo platform will be sunset after all customers migrate, with migration expected to begin in H2 2026. The core Lumigo capabilities (graph view, Lambda functions page, payload capture) will be rebuilt inside Dash0, but that rebuilt version will be a different product with different pricing, different interfaces, and potentially different behavior.
| Architecture aspect | Better Stack | Lumigo |
|---------------------|-------------|--------|
| **Instrumentation** | eBPF kernel-level, zero code | Auto-instrumented Lambda + OTel for containers |
| **Payload capture** | Network-level traces | Full request/response payloads for Lambda |
| **Kubernetes** | First-class (eBPF DaemonSet) | Supported, historically secondary |
| **Serverless (AWS Lambda)** | OTel-based | Best-in-class native |
| **Query language** | SQL + PromQL (unified) | UI-first; limited custom querying |
| **Platform continuity** | Independent, stable | Sunset into Dash0 by end of 2026 |
| **OpenTelemetry** | Native, first-class | Supported; own tracers recommended |
## Pricing comparison
Lumigo's pricing page shows tiered plans based on trace count and log volume (redirecting new signups to Dash0 pricing). The published tiers (Basic free, Standard at $99/month, Plus at $299/month) reflect Dash0's pricing model, as Lumigo's own platform transitions. For the existing Lumigo platform, pricing was trace-count-based (charged per ingested trace) with separate log ingestion fees. G2 reviewers flagged that at production volumes, costs could escalate unpredictably, particularly for high-throughput Lambda environments.
Better Stack pricing is volume-based: you pay for GB ingested and GB stored across all signal types, with no per-host, per-trace-count, or per-feature charges.
### Better Stack: volume-based, no trace-count billing
Better Stack charges based on actual data volume with no hidden multipliers. The formula is: data volume, responders, monitors.
**Pricing structure:**
- Logs: $0.10/GB ingestion + $0.05/GB/month retention (all searchable, no indexing fee)
- Traces: $0.10/GB ingestion + $0.05/GB/month retention (no span indexing)
- Metrics: $0.50/GB/month (no cardinality penalties)
- Error tracking: $0.000050 per exception
- Responders: $29/month (unlimited phone and SMS)
- Monitors: $0.21/month each
**No cardinality penalties, no high-water mark billing, no trace count limits.** Costs scale linearly with actual usage, regardless of how many individual Lambda invocations or requests you process.
### Lumigo: trace-count-based pricing with volume risk
Lumigo's original pricing model charged per ingested trace, with separate metering for log volume. For Lambda-heavy teams, this created a specific cost pressure: high-throughput functions can generate millions of traces per month, and trace count billing scales directly with invocation frequency. G2 reviewers noted that hitting trace limits unexpectedly would require plan upgrades, and that costs became significant at scale.
The pricing visible at lumigo.io today reflects Dash0's tiers (since Lumigo redirects signups there), which includes trace count limits at each tier (150k traces on free, 1M on Standard at $99/month, 5M on Plus at $299/month). Custom/enterprise pricing requires contacting sales.
Does your Lambda environment process more than 5 million invocations per month? At trace-count pricing, that immediately lands you in enterprise custom territory. Better Stack's GB-based pricing makes those numbers irrelevant: what matters is data volume, not invocation count.
**Lumigo pricing gaps:**
- No built-in incident management: requires PagerDuty, OpsGenie, or similar (add $49-83/user/month)
- No status pages included
- On-call scheduling not included
- Error tracking not included as a standalone capability
Better Stack includes all of these. If you are currently running Lumigo alongside PagerDuty, you are already paying for a product stack that Better Stack collapses into one bill.
### Cost comparison: 3-year TCO
For a team of 5 on-call responders running a Lambda-heavy AWS environment:
| Category | Better Stack | Lumigo + tools |
|----------|-------------|----------------|
| Platform (logs, metrics, traces) | $33,600 | ~$10,764 (Plus plan × 36 mo) |
| Incident management | $5,220 | $21,600 (PagerDuty) |
| Status pages | $4,464 | Not available |
| Error tracking | $9,000 | Not available |
| Migration cost (Lumigo to Dash0) | $0 | Engineering time + re-instrumentation |
| **Total** | **$52,284** | **$32,364+ (incomplete stack)** |
At the Plus plan, Lumigo alone is cheaper for pure trace+log observability. Better Stack's TCO advantage comes from what Lumigo does not include: incident management, status pages, and error tracking. If you need those capabilities (most production teams do), you are buying them separately.
There is also a category of cost that does not appear on invoices: the engineering time required to migrate from Lumigo to Dash0 by end of 2026. Migrating instrumentation, dashboards, alerts, and integrations has a real cost. Better Stack has no mandatory migration on the horizon.
| Pricing aspect | Better Stack | Lumigo |
|----------------|-------------|--------|
| **Pricing model** | Data volume (GB) | Trace count + log volume |
| **Trace count limits** | None | Per-tier (1M-5M+) |
| **Incident management** | Included ($29/responder) | External tools required |
| **Status pages** | Included | Not available |
| **Error tracking** | Included | Not included |
| **Cardinality penalty** | None | N/A |
| **Migration risk** | None | Forced migration to Dash0 |
## Distributed tracing
Tracing is where Lumigo has historically been strongest, and where the comparison is most nuanced. Both platforms deploy auto-instrumentation without code changes. The difference is what they capture and where they work best.
### Better Stack: eBPF-based tracing with frontend correlation
[Better Stack's APM](https://betterstack.com/tracing) uses eBPF to capture distributed traces at the kernel level. Deploy the collector to Kubernetes and HTTP/gRPC traffic between services is traced immediately. Database calls to PostgreSQL, MySQL, Redis, and MongoDB are captured automatically, including query details.
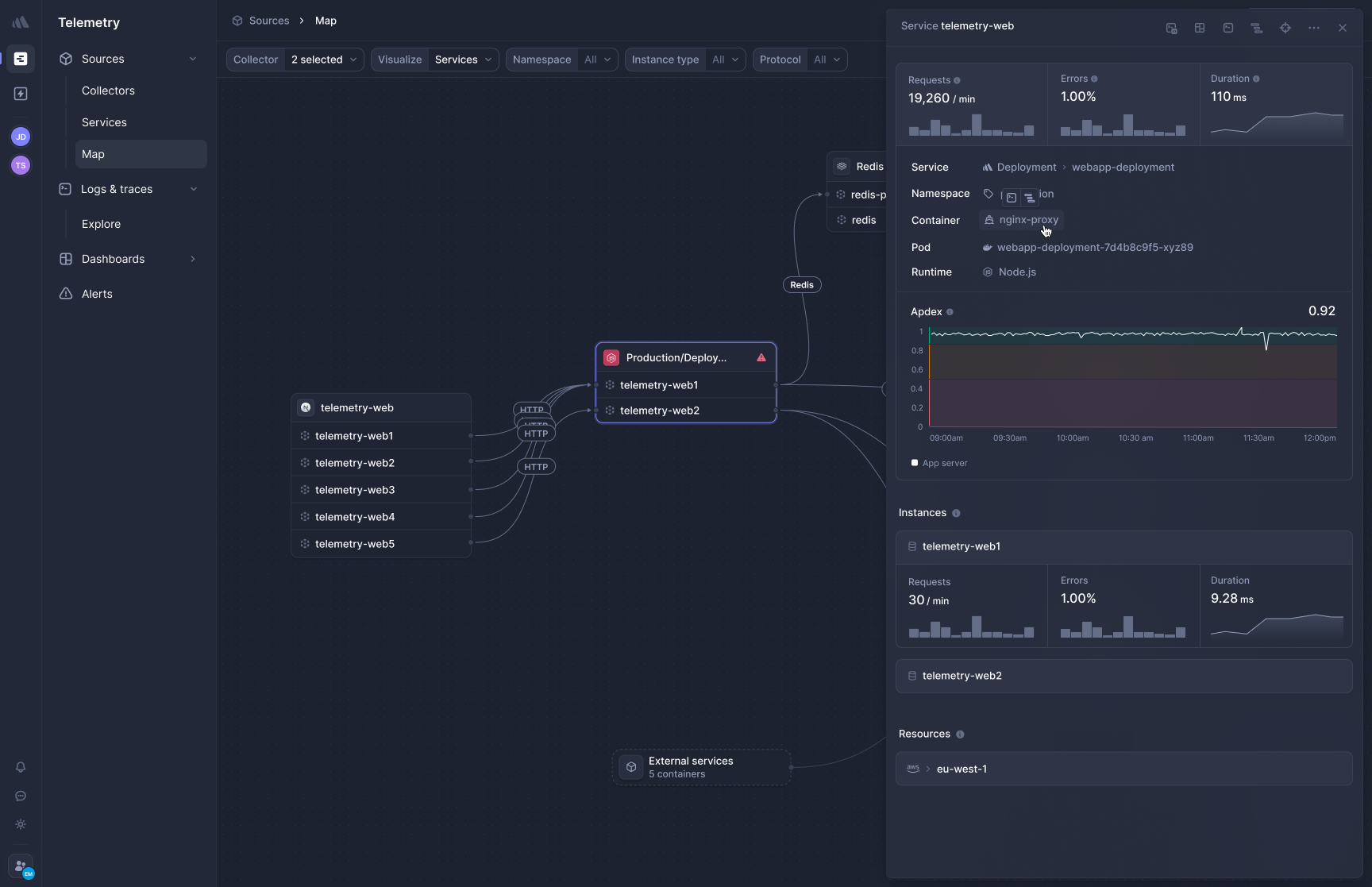
Here is how Better Stack visualizes and navigates distributed traces:
**Frontend-to-backend correlation** links what users experience in the browser to what happened in your backend services during that request. A slow page load traces from the frontend event through your API services and database queries in a single view, without manually connecting RUM sessions to backend spans.
**OpenTelemetry-native with zero lock-in.** Traces use the OTel format natively. If you decide to route telemetry elsewhere, you change a config line. There are no proprietary agents to rip out and no migration tax. How much would it cost your team to switch away from a proprietary tracing format today? Whatever that number is, Better Stack keeps it at zero.
Better Stack's tracing is built for polyglot environments: Python, Go, Java, Ruby, Node.js, and more, all instrumented by the same eBPF collector without per-language library management.
### Lumigo: payload-level tracing for AWS-native environments
Lumigo's distributed tracing captures something most tracing platforms do not: the full request and response payloads for AWS managed service calls. When your Lambda function calls DynamoDB, SQS, or EventBridge, Lumigo shows you exactly what was sent and received, not just the span metadata. For debugging complex event-driven workflows where the payload content is the bug (a malformed message, an unexpected response structure, a missing field), this visibility is genuinely faster than reconstructing context from logs.

Lumigo also provides visual service maps that update automatically, showing the live state of your Lambda-to-managed-service dependency graph. Per Gartner Peer Insights reviewers, this architectural clarity helped teams identify blast radius during incidents and understand propagation paths across event-driven systems.
Where does Lumigo's tracing fall short? Container and Kubernetes tracing has been acknowledged as a secondary capability, with G2 reviewers noting that Lambda tracing is significantly more mature. Lumigo's traces also use Lumigo's own format and tooling, meaning you are tied to their interface and query model. As the platform transitions to Dash0, your existing trace data and the dashboards built on it will need to be migrated.
**What does Better Stack not do?** eBPF operates at the network layer, so it captures what goes between services, not the contents of application-level message payloads inside those calls. Lumigo's payload capture gives you the body of the SQS message or the DynamoDB item content; Better Stack's tracing shows the call duration, status, and metadata. For teams whose bugs live inside event payloads (malformed data, schema mismatches), Lumigo's approach surfaces the issue faster. For everything else, eBPF's zero-code coverage at scale is the stronger default.
| Tracing feature | Better Stack | Lumigo |
|-----------------|-------------|--------|
| **Instrumentation** | eBPF (zero code, kernel-level) | Auto-instrumented Lambda + OTel |
| **Lambda tracing** | Yes (OTel-based) | Best-in-class (payload-level) |
| **Container/K8s tracing** | First-class | Secondary; historically less mature |
| **Payload capture** | Network-level metadata | Full request/response payloads |
| **Frontend correlation** | Unified view (RUM + traces) | Not available |
| **Service maps** | Yes | Yes (visual graph-first) |
| **OpenTelemetry** | Native, no lock-in | Supported; own tracers recommended |
| **Polyglot support** | Yes (single eBPF collector) | Language-specific tracers |
| **Data portability** | Full (OTel format) | Limited (Lumigo-hosted format) |
## Serverless observability
Serverless is where Lumigo made its name. It is also where the platform's future is most uncertain, given the Dash0 acquisition. This section covers both platforms' Lambda and serverless capabilities honestly.
### Better Stack: OpenTelemetry-native Lambda support
Better Stack supports Lambda and other serverless runtimes through OpenTelemetry-based instrumentation. Add the OTel layer to your Lambda function, configure the endpoint to point at Better Stack's collector, and function invocations flow into the same unified data warehouse as your Kubernetes services and infrastructure metrics. You query them with the same SQL syntax.
The practical benefit in a mixed environment (some services on Lambda, some on Kubernetes, some on EC2) is a single query language and a single interface for everything. You do not switch contexts or query tools depending on where a service runs.
If you are already using OpenTelemetry in your stack, here is how to configure the collector to send data to Better Stack:
### Lumigo: purpose-built for Lambda and AWS managed services
This is Lumigo's strongest category, and it deserves a direct acknowledgment. Lumigo was built from the ground up to instrument AWS Lambda and managed services. Its tracing layer intercepts function invocations and captures the full payload of calls to SQS, DynamoDB, SNS, EventBridge, Step Functions, and other AWS services. For teams whose production workloads are entirely or predominantly on Lambda, the diagnostic depth Lumigo provides is faster to reach than anything OTel-based tracing gives you out of the box.
Key capabilities per the Lumigo serverless page:
- Zero-code Lambda instrumentation with one-click setup
- Full payload capture for AWS SDK calls (the actual data, not just the span)
- Visual service maps showing Lambda-to-managed-service dependencies in real time
- Serverless-specific smart alerts (cold start detection, timeout prediction, memory threshold alerts)
- AI-driven root cause analysis surfacing issues in Lambda execution context

The honest caveat: all of this is being rebuilt into Dash0. The Dash0 FAQ confirms that Lambda tracer support, the graph view, and the Lambda functions page will be migrated into Dash0 during H2 2026. The capability you buy from Lumigo today will exist in Dash0 tomorrow, but on Dash0's terms, interface, and pricing. What will that look like? It is not fully defined yet.
If serverless-first Lambda observability is your primary requirement and platform stability is not a concern over the next 12 months, Lumigo is still the most purpose-built option available. If you want to invest in a platform that will still be called the same thing and work the same way in 18 months, Better Stack is the more defensible choice.
| Serverless feature | Better Stack | Lumigo |
|-------------------|-------------|--------|
| **Lambda instrumentation** | OTel-based | Native, purpose-built |
| **Payload capture** | Network metadata | Full request/response payloads |
| **AWS managed services** | Via OTel instrumentation | Deep native support (SQS, DynamoDB, etc.) |
| **Cold start detection** | Via trace latency | Native serverless-specific alerts |
| **Visual service maps** | Yes | Yes (Lambda-graph-first) |
| **Platform stability** | Independent, stable | Sunset into Dash0 by end of 2026 |
## Log management
### Better Stack: all logs searchable, no indexing decisions
[Better Stack logs](https://betterstack.com/logs) stores all ingested logs as structured data in the same warehouse as traces and metrics. Every log is immediately searchable with no indexing fees and no decision about which logs are worth making searchable. The pricing is $0.10/GB ingestion plus $0.05/GB/month retention, regardless of query frequency or volume.
Watch how Better Stack's Live Tail provides real-time log streaming with filtering:
Query logs with SQL alongside your metrics and traces:
```sql
SELECT
service_name,
COUNT(*) as error_count,
AVG(duration_ms) as avg_duration
FROM logs
WHERE level = 'error'
AND timestamp > NOW() - INTERVAL '1 hour'
GROUP BY service_name
ORDER BY error_count DESC
```
Turn those queries into charts directly:
Logs from many teams use Vector for pipeline processing. Better Stack integrates natively:
### Lumigo: logs unified with traces, aimed at Lambda context
Lumigo's log management connects logs directly to traces, which is genuinely useful in Lambda environments where a single invocation produces both a trace and function-level log output. The platform ingests logs from Lambda functions, enriches them with trace context (request ID, invocation metadata), and displays them alongside the trace in the same view. The Lumigo pricing page shows log ingestion metered separately from traces (40GB/month on Standard, 100GB/month on Plus).
What Lumigo does not offer that Better Stack does: a universal SQL query layer across logs, metrics, and traces; live tail with custom filtering presets; and searchable retention that scales to any volume without tier-based caps. G2 reviewers noted that log management is not Lumigo's primary strength and that teams with serious log volume requirements often supplemented it with other tools.
| Log management | Better Stack | Lumigo |
|----------------|-------------|--------|
| **Searchability** | 100% of ingested logs | All logs (correlated with traces) |
| **Query language** | SQL + PromQL | UI-driven; limited custom query |
| **Pricing model** | $0.10/GB ingestion + $0.05/GB retention | Log volume per tier ($0/40GB/100GB+) |
| **Retention** | Flexible (pay per GB per month) | 3-30 days depending on tier |
| **Live tail** | Yes (with presets and filters) | Yes |
| **Trace correlation** | Automatic | Automatic (strong in Lambda context) |
| **Vector integration** | Native | Not documented |
## Metrics and infrastructure monitoring
### Better Stack: Prometheus-compatible, no cardinality costs
[Better Stack metrics](https://betterstack.com/infrastructure-monitoring) uses data volume as the sole billing dimension. Add high-cardinality tags freely, no cost multipliers for unique time series combinations. Full PromQL support for anyone already running Prometheus exporters.
Here is how to build metrics dashboards:
Write PromQL queries directly:
Or use the drag-and-drop chart builder if you prefer a visual approach:
### Lumigo: metrics as a supporting capability
Lumigo's metrics offering (available at lumigo.io/metrics) positions metrics as monitoring for application-level performance, not as infrastructure observability in the traditional sense. The platform collects Lambda-specific metrics (invocation count, duration, error rate, cold starts, concurrency) and surfaces them in dashboards alongside traces. Custom metrics are supported.
What Lumigo's metrics do not cover well: host-level infrastructure monitoring, Prometheus exporter scraping, PromQL queries, or the kind of cardinality-heavy custom metrics typical in Kubernetes environments. G2 reviewers rated Lumigo highly for Lambda function metrics but noted limited coverage outside AWS-native workloads. If you are running mixed infrastructure (some Lambda, some K8s, some bare metal), Lumigo's metrics picture is incomplete. You would need a separate tool to cover non-serverless infrastructure.
| Metrics feature | Better Stack | Lumigo |
|-----------------|-------------|--------|
| **Prometheus support** | Native PromQL | Not primary |
| **Infrastructure monitoring** | Full host/K8s coverage | Lambda-centric |
| **Custom metrics** | Yes (no cardinality penalty) | Yes |
| **Cardinality model** | Volume-based, no penalty | Not a primary pricing concern |
| **Non-AWS coverage** | Full (any infra) | Limited outside AWS |
## Lumigo Copilot and AI features
### Better Stack: AI SRE and MCP server (GA)
Better Stack's AI SRE activates automatically during incidents. It examines the service map, queries recent logs, reviews deployment history, and proposes likely root causes before you have opened a terminal window. At 3am, that head start matters.
The [Better Stack MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/) connects Claude, Cursor, and other MCP-compatible AI assistants directly to your observability data. Instead of copying log snippets into a chat window, your AI assistant queries Better Stack directly: running SQL against your logs, checking on-call schedules, acknowledging incidents, or building dashboard queries through natural language.
```json
{
"mcpServers": {
"betterstack": {
"type": "http",
"url": "https://mcp.betterstack.com"
}
}
}
```
MCP coverage includes uptime monitoring, incident management, log querying, metrics, dashboards, error tracking, and on-call scheduling. The MCP server is generally available to all customers today.
### Lumigo Copilot: alert-to-RCA in the Lumigo interface
Lumigo Copilot is positioned as AI-powered observability: intelligent alerts that summarize issues with context, automated root cause analysis, and AI-driven triage within the Lumigo platform. The Copilot page describes it as "the only solution that correlates request and response payloads with traces, logs, and metrics to identify and remediate issues."

The payload correlation is the key differentiator here. Because Lumigo captures full request and response bodies, its AI layer can reason about the actual content of failed calls, not just their status codes and durations. In Lambda environments where a malformed event payload is the root cause, Copilot can surface that directly.
What Lumigo Copilot does not offer: an MCP server for AI assistant integration, autonomous pre-incident investigation, or AI-assisted debugging for code editors like Cursor or Claude Code. The AI operates within Lumigo's own interface. There is no API surface for external AI tooling to access observability data programmatically.
Lumigo Copilot's advanced features (AI RCA, AI insights, AI issue triage, Copilot in Slack and Teams) are enterprise-tier only (Custom plan, contact sales). The Standard and Plus plans include "Copilot Basic," which covers intelligent alerts but not full automated root cause analysis.
Is your team using AI coding assistants already? If so, Better Stack's MCP integration connects those tools directly to your production telemetry. Lumigo's Copilot keeps the AI inside Lumigo's own product boundary.
| AI feature | Better Stack | Lumigo |
|-----------|-------------|--------|
| **Autonomous incident investigation** | Yes (AI SRE, activates on alert) | Yes (Copilot, enterprise tier) |
| **MCP server** | Yes (GA, all customers) | No |
| **Payload-aware AI analysis** | No (network-level traces) | Yes (full request/response context) |
| **Slack/Teams AI integration** | Via MCP | Enterprise tier only |
| **AI coding assistant integration** | Claude Code + Cursor via MCP | Not available |
| **Natural language log queries** | Via MCP in any AI client | Within Lumigo UI only |
## Incident management
Better Stack includes on-call scheduling, escalation policies, unlimited phone and SMS alerts, and Slack-native incident management at $29/month per responder. Lumigo has no incident management product. When a Lumigo alert fires, it sends a notification to Slack, email, PagerDuty, or OpsGenie. The actual incident response workflow happens elsewhere.
### Better Stack: end-to-end incident lifecycle
[Better Stack incident management](https://betterstack.com/incident-management) covers the full loop: alert fires, incident is declared, on-call engineer is notified via phone or SMS, incident channel opens in Slack, team investigates with AI-assisted context, incident is resolved, post-mortem is generated automatically.
Incidents managed directly in Slack, where your team already is:
On-call rotation management with timezone-aware scheduling:
Automatic post-mortems generated from incident timelines:
For enterprise escalation workflows, Better Stack supports multi-tier policies with time-based rules:
### Lumigo: alerting only, no incident management
Lumigo sends alerts. Per its integration list, it supports Slack, email, PagerDuty, OpsGenie, VictorOps, and Microsoft Teams for notification routing. Smart alerts include Lambda-specific signals: cold start rate increases, function timeout risk, memory threshold proximity, and error rate spikes.
What Lumigo does not have: on-call scheduling, escalation policies, phone/SMS delivery, incident timelines, post-mortems, or status pages. Are you currently using Lumigo alongside PagerDuty or OpsGenie for on-call management? That combination is common among Lumigo users, and it means you are already paying for a product that Better Stack includes. For 5 responders, that external tool adds $245-415/month that Better Stack replaces with $145/month.
| Incident feature | Better Stack | Lumigo |
|-----------------|-------------|--------|
| **On-call scheduling** | Built-in | Not available |
| **Phone/SMS alerts** | Unlimited ($29/responder) | Via PagerDuty/OpsGenie |
| **Escalation policies** | Built-in | Via external tools |
| **Slack-native incidents** | Native | Alert routing only |
| **Post-mortems** | Automatic | Not available |
| **Status pages** | Built-in | Not available |
| **5-responder monthly cost** | $145 | $245-415 (external tool required) |
## AI agent observability
This is one of Lumigo's newer and more interesting capabilities, and one where it genuinely covers ground Better Stack does not.
### Lumigo: LLM and AI agent visibility
Lumigo's AI Agent Observability product instruments AI agent workflows directly: capturing every prompt sent to an LLM, every response returned, every tool call made, and the token usage and latency across each step. For teams building production AI applications (LangChain pipelines, OpenAI function-calling agents, multi-step reasoning systems), this is the kind of visibility that application-level tracing cannot provide without custom instrumentation.

Specific capabilities per the Lumigo AI agent page:
- Full prompt and response capture across LLM calls
- Token usage tracking per model, team, and endpoint
- Latency tracking across agent decision steps
- Cost analysis per agent workflow
This capability is directly relevant to the Dash0 acquisition rationale: the announcement cited Lumigo's "LLM observability capabilities" as a key reason for the deal. It will presumably survive the migration into Dash0, but the transition timeline is Q3-Q4 2026.
### Better Stack: no LLM-native agent observability
Better Stack does not have a dedicated LLM or AI agent observability product today. You can capture logs and traces from AI application services like any other service (function duration, error rates, dependency calls), but there is no prompt/response capture, token usage tracking, or agent workflow visualization.
If you are building production AI agents and that observability layer is a core requirement, Lumigo (or Dash0, post-migration) has genuine depth here that Better Stack does not currently match. This is an honest gap, worth acknowledging.
| AI agent observability | Better Stack | Lumigo |
|-----------------------|-------------|--------|
| **Prompt/response capture** | No | Yes |
| **Token usage tracking** | No | Yes |
| **Agent workflow visualization** | No | Yes |
| **LLM cost analysis** | No | Yes |
| **Platform stability** | Stable | Transitioning to Dash0 |
## Kubernetes observability
### Better Stack: eBPF-native Kubernetes monitoring
Kubernetes is a core Better Stack deployment target. The eBPF collector runs as a DaemonSet across all nodes, automatically discovering pods, services, and ingress traffic without any per-pod configuration. Traces, logs, and metrics from all workloads flow into the same unified store.
Deploy Better Stack's collector to a Kubernetes cluster:
```yaml
helm repo add betterstack https://charts.betterstack.com
helm install betterstack betterstack/collector \
--set token=
```
From there, service-to-service HTTP calls are traced, database queries are captured, and infrastructure metrics (CPU, memory, network, disk) are collected automatically from all nodes. No per-service SDK configuration. No sampling decisions to make.
### Lumigo: Kubernetes as a secondary capability
Lumigo supports Kubernetes observability through its Kubernetes Observability product, which instruments containerized applications using an operator-based auto-injection approach. The operator injects Lumigo's tracer into pods at startup, enabling distributed tracing without Dockerfile changes.

The honest context here, supported by G2 reviews, is that Lumigo's Kubernetes coverage has historically been less complete than its Lambda coverage. Reviews note that "container tracing is not yet up to par with the Lambda ones" and that the product is "headed in the right direction." Lumigo's architecture was Lambda-first, and Kubernetes was added later.
Additionally, with the Dash0 acquisition, Lumigo's Kubernetes observability roadmap is now Dash0's roadmap. Development priorities for the Lumigo Kubernetes product are being absorbed into Dash0's platform decisions, which means independent product improvements to Lumigo Kubernetes are unlikely during the transition period.
| Kubernetes feature | Better Stack | Lumigo |
|-------------------|-------------|--------|
| **Instrumentation** | eBPF DaemonSet (zero config) | Operator-based auto-injection |
| **Trace coverage** | Full (HTTP, gRPC, DB) | Good; historically secondary to Lambda |
| **Infrastructure metrics** | Full node + pod metrics | Application-level focus |
| **Deployment complexity** | Single Helm chart | Operator installation + configuration |
| **Roadmap ownership** | Independent | Being absorbed into Dash0 |
## Status pages
### Better Stack: built-in, multi-channel
[Better Stack Status Pages](https://betterstack.com/status-pages) is included with the platform and syncs automatically with incident management. When an incident is declared, the status page updates. When it resolves, the page reflects that without manual action.
Subscriber notifications go out via email, SMS, Slack, and webhook. Custom branding, custom domains, password protection, and SAML SSO for private pages are all available.
### Lumigo: no status pages
Lumigo does not offer status pages. If you need external communication during incidents (customer-facing status, subscriber notifications, scheduled maintenance announcements), you need a separate tool.
| Status pages | Better Stack | Lumigo |
|-------------|-------------|--------|
| **Available** | Yes (included) | No |
| **Incident sync** | Automatic | N/A |
| **Subscriber notifications** | Email, SMS, Slack, webhook | N/A |
## Enterprise readiness
Which platform should your procurement team evaluate for enterprise deployment?
Better Stack covers the compliance and access control requirements most enterprise processes need: SOC 2 Type II, GDPR, SSO via Okta/Azure/Google, SCIM provisioning, RBAC, audit logs, and data residency options. Enterprise customers get a dedicated Slack support channel and a named account manager.
Lumigo has GDPR compliance and SOC 2 certification (per its security page), with SSO support and role-based access. However, there is a material concern for enterprise procurement: Lumigo is a platform with a confirmed end-of-life timeline. Enterprise contracts signed today will require migration to Dash0 before or by end of 2026. For organizations with long procurement cycles, this means evaluating not just Lumigo but the Dash0 platform you are implicitly committing to migrate toward.
Does your procurement process include evaluating vendor continuity? If so, the Lumigo-to-Dash0 transition should be an explicit discussion point, not a footnote.
| Enterprise feature | Better Stack | Lumigo |
|-------------------|-------------|--------|
| **SOC 2 Type II** | ✓ | ✓ |
| **GDPR** | ✓ | ✓ |
| **HIPAA** | ✗ | ✗ |
| **SSO (SAML/OIDC)** | ✓ (Okta, Azure, Google) | ✓ |
| **SCIM provisioning** | ✓ | Not documented |
| **RBAC** | ✓ | ✓ |
| **Audit logs** | ✓ | ✓ |
| **Data residency** | EU + US regions, optional S3 | Not documented |
| **Dedicated support channel** | Slack + named account manager | Customer success (enterprise) |
| **SLA** | Enterprise SLA available | Enterprise SLA available |
| **Platform continuity** | Independent, no forced migration | Forced migration to Dash0 by end of 2026 |
## Final thoughts
For most teams evaluating observability in 2026, Better Stack is the more defensible choice. Lumigo's Lambda observability remains genuinely strong, its payload capture is a real differentiator, and its AI agent observability is ahead of where Better Stack is today. But those strengths come with an asterisk: you are buying a platform that requires a forced migration to Dash0 by the end of 2026, and the future version of those capabilities will look different from what Lumigo offers today.
**Better Stack is the stronger pick if your infrastructure spans more than Lambda alone.** It wins on incident management, status pages, and on-call scheduling in a single platform, on pricing that scales with data volume rather than trace count, and on MCP integration that connects AI assistants directly to your production telemetry. If platform stability matters to your organization, there is no meaningful uncertainty on the Better Stack side of that equation.
Lumigo has the genuine edge in two situations: your workloads are predominantly AWS Lambda and payload-level visibility into event-driven call chains is a core debugging requirement, or you are building production AI agents and need LLM prompt and response observability today.
The decision to evaluate Lumigo is effectively a decision to evaluate Dash0. That is not necessarily wrong, but it should be explicit.
Ready to see the difference? [Start your free trial](https://betterstack.com) and deploy the eBPF collector to your Kubernetes cluster or configure the OTel endpoint for your Lambda functions. You will have traces flowing within the hour.