# Better Stack vs groundcover: A Complete Comparison for 2026
If you're weighing groundcover against Better Stack, you're probably trying to solve the same problem: escape Datadog's bill without losing visibility into your production stack. Both platforms pitch themselves as the answer. They take very different routes to get there.
groundcover is a Kubernetes-native observability platform built around two bets: **eBPF for data collection** and **Bring Your Own Cloud (BYOC) for data storage**. Your telemetry never leaves your AWS or GCP account. Pricing is per monitored node rather than per GB ingested, which eliminates the "bill shock" problem that drives teams away from Datadog in the first place. It covers infrastructure monitoring, APM, log management, RUM, and LLM observability in one unified product.
Better Stack covers the same observability ground and then extends past it, **bundling incident management, on-call scheduling, status pages, error tracking, and uptime monitoring into the same platform** at volume-based pricing with no node counting, no BYOC infrastructure bill, and no Kubernetes requirement.
## Quick comparison at a glance
| Category | Better Stack | groundcover |
|----------|--------------|-------------|
| **Deployment model** | Managed SaaS (optional S3 for self-hosted data) | BYOC-native (runs in your AWS/GCP VPC) |
| **Infrastructure scope** | Kubernetes, Docker, VMs, serverless, bare metal | Kubernetes + Linux hosts (K8s-first) |
| **Instrumentation** | eBPF + OpenTelemetry, zero code changes | eBPF + OpenTelemetry, zero code changes |
| **Pricing model** | Volume-based (GB ingested + responders) | Per-node ($30-$50/node/month) + BYOC hosting |
| **Incident management** | Built-in (on-call, escalation, phone/SMS) | Not included (integrate incident.io/PagerDuty) |
| **Status pages** | Built-in | Not included |
| **Error tracking** | Built-in, Sentry SDK compatible | Not a dedicated product (Issues view) |
| **AI SRE + MCP** | AI SRE + MCP server (GA) | AI Mode (Bedrock, GA) + MCP server |
| **Enterprise compliance** | SOC 2 Type II, GDPR | SOC 2 Type II, ISO 27001 |
| **Integrations** | 100+ covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more | OTel, Prometheus, AWS/GCP/Azure, Slack, PagerDuty, Jira, CI/CD |
## Platform architecture
The architectural split between these two platforms is fundamental. Better Stack runs as managed SaaS with unified storage for logs, metrics, and traces behind one query layer. groundcover runs inside your own cloud account, with the data plane (ClickHouse, VictoriaMetrics, collectors) deployed and managed by groundcover in your VPC, and only the UI hosted externally. Which model is right for you? It depends on one question: does your telemetry have to stay in your cloud?
### Better Stack: unified SaaS with optional data self-hosting
Better Stack's architecture rests on three principles: eBPF-based auto-instrumentation, OpenTelemetry-native ingest, and unified storage that treats logs, metrics, and traces as wide events in a single ClickHouse-backed warehouse. To see how the collector discovers services without code changes, watch this:
**The eBPF collector** runs at the kernel level on Kubernetes nodes (and works on Docker, VMs, and other Linux environments). It auto-discovers services, instruments HTTP and gRPC traffic, and traces database queries to PostgreSQL, MySQL, Redis, and MongoDB, all without touching application code.
**Unified storage** means logs, metrics, and traces sit in the same data warehouse and answer to the same query languages: SQL and PromQL. Everything ingested is searchable immediately, with no indexing tier and no choose-what-to-keep tradeoff.
**A single interface** surfaces service maps, logs, metrics, and traces together. When an alert fires, you don't navigate between products to assemble context. For teams that want data residency control, Better Stack also supports optional S3-based self-hosted storage, though the default managed SaaS model covers most customers.

### groundcover: BYOC-native architecture
groundcover's defining architectural decision is that it was built BYOC-first. Every deployment runs inside the customer's own AWS or GCP account. There's a separation between control plane (groundcover's cloud, handles metadata, routing, user management) and data plane (your cloud, handles ingest, processing, and storage via ClickHouse and VictoriaMetrics).
**The eBPF sensor** runs as a DaemonSet on your Kubernetes nodes, collecting logs, metrics, traces, and Kubernetes events from the kernel. It also supports standalone Linux hosts. Like Better Stack, it requires no application code changes.
**The in-cloud backend** is deployed in your VPC and fully managed by groundcover. This is the model's biggest strength and biggest constraint. The strength: your observability data, including potentially sensitive log contents and full LLM payloads, never leaves your cloud. The constraint: you pay for the VPC infrastructure that hosts it. groundcover's own TCO calculator shows a medium-scale 450-node deployment adds roughly $23,000/year in BYOC hosting (EC2, EBS, S3) on top of the $180,000/year license.
**Kubernetes is effectively required.** groundcover's architecture, documentation, and deployment guides are all Kubernetes-first. If you're running workloads on VMs, ECS, or bare metal and not on EKS/GKE/AKS, the platform fits less naturally.
[SCREENSHOT: groundcover BYOC architecture diagram](https://imagedelivery.net/xZXo0QFi-1_4Zimer-T0XQ/da3671e2-e14e-4db9-76ea-3b7946028c00/md2x =1628x710)
| Architecture aspect | Better Stack | groundcover |
|---------------------|--------------|-------------|
| **Deployment model** | Managed SaaS | BYOC (runs in your VPC) |
| **Data storage location** | Better Stack cloud (optional S3 self-host) | Inside your AWS/GCP account |
| **Runtime requirement** | Any Linux environment | Kubernetes-native (K8s required for full value) |
| **Infrastructure overhead** | None (fully managed) | Your VPC resources (managed by groundcover) |
| **Query language** | SQL + PromQL (universal) | SQL + PromQL (embedded Grafana) |
| **Storage engine** | ClickHouse-backed warehouse | ClickHouse + VictoriaMetrics |
| **Time to first insight** | Minutes after collector deploy | Hours (includes VPC provisioning) |
| **OpenTelemetry support** | First-class native | First-class native |
## Pricing comparison
This is where the two platforms diverge most visibly. Better Stack prices on data volume (GB ingested plus responders). groundcover prices on node count plus your VPC hosting bill. Neither model is wrong. They serve different shapes of workload. A data-heavy team with relatively few nodes will cost less on groundcover. A team with many nodes running quieter workloads will cost less on Better Stack.
### Better Stack: volume-based with no per-host surcharges
Better Stack charges for what you actually send. No per-host fees, no cardinality penalties, no BYOC infrastructure bill to budget around.
**Pricing structure:**
- Logs: $0.10/GB ingestion + $0.05/GB/month retention (all searchable, no indexing fees)
- Traces: $0.10/GB ingestion + $0.05/GB/month retention
- Metrics: $0.50/GB/month (no cardinality penalties)
- Error tracking: $0.000050 per exception
- Responders: $29/month (unlimited phone/SMS alerts)
- Monitors: $0.21/month each
**100-node deployment example:** $791/month
- Telemetry (2.5TB/month): $375
- 5 Responders (with unlimited phone/SMS): $145
- 100 Monitors: $21
- Error tracking (5M exceptions): $250
Because the model is volume-based, you pay for data you actually generate, not for the size of your cluster. Have you ever been charged for hosts that were barely emitting telemetry because they were sitting idle? That doesn't happen here.
### groundcover: per-node with BYOC hosting costs
groundcover's pricing, as of its April 2026 self-serve launch, works like this:
- **Free tier:** $0 forever, 12-hour retention, community Slack support, no host limit
- **Pro:** $30 per host per month, includes all integrations, SSO, standard retention, standard support
- **Enterprise:** $35 per host per month, adds RBAC and unlimited data retention
- **On-Premise:** $50 per host per month, fully on-prem deployment with isolated authentication
Plans are priced on monthly average host count rather than peak, which avoids the high-water-mark billing trap that Datadog is famous for. All tiers are available on a month-to-month basis through AWS Marketplace and GCP Marketplace.
**The hidden line item is BYOC hosting.** Because groundcover runs in your VPC, you pay your cloud provider for the underlying EC2, EBS, S3, and networking. groundcover's public TCO calculator gives a sense of scale:
| Scenario | License (Pro) | BYOC hosting | Annual total |
|----------|---------------|--------------|--------------|
| 50 nodes | $18,000 | ~$3,500 | ~$21,500 |
| 450 nodes (medium scale) | $162,000 | ~$23,343 | ~$185,343 |
| 1,900 nodes (large scale) | ~$684,000 | ~$95,000+ | ~$779,000+ |
*Based on groundcover's own published TCO calculator figures. BYOC hosting costs scale with data volume and retention requirements, so the same node count with heavy logging produces materially different hosting bills.*
**100-node deployment example (groundcover Pro):** ~$36,000/year license + ~$7,000/year BYOC hosting = **~$3,580/month**
That's roughly 4.5x Better Stack's equivalent 100-node cost. However: if you have heavy data volume (say 10TB/month of logs), the calculation inverts. groundcover's flat per-node pricing starts looking very competitive because logging volume doesn't change the license. This is the single most important thing to model before choosing between the two.
Why does this matter? Because the "cheaper" platform depends entirely on your ratio of data to infrastructure. Teams with small clusters and heavy instrumentation save with Better Stack. Teams with large clusters and modest per-node data volumes save with groundcover.
### 3-year TCO comparison (100 nodes, moderate data volume)
| Category | Better Stack | groundcover |
|----------|--------------|-------------|
| Platform license | $28,500 | $108,000 |
| BYOC hosting (your cloud bill) | Included | ~$21,000 |
| APM/tracing | Included | Included |
| Error tracking | $9,000 | Included (as Issues) |
| Incident management (on-call + phone/SMS) | $5,220 | ~$21,600 (incident.io/PagerDuty) |
| Status pages | Included | ~$2,000 (separate tool) |
| Engineering overhead | $0 | ~$15,000 (BYOC ops + integrations) |
| **3-year total** | **~$42,720** | **~$167,600** |
*Assumes 100 nodes with 2.5TB/month telemetry. Swap to a data-heavy 50-node deployment and groundcover's numbers compress substantially. This is why you should model your specific workload rather than trust generic benchmarks.*
## Application performance monitoring
APM is the category where groundcover and Better Stack are most directly comparable. Both use eBPF for zero-code instrumentation. Both support OpenTelemetry natively. The real differences come down to where the data lives, what runs outside Kubernetes, and whether frontend-to-backend correlation is first-class or requires configuration.
### Better Stack: eBPF APM with frontend-to-backend correlation
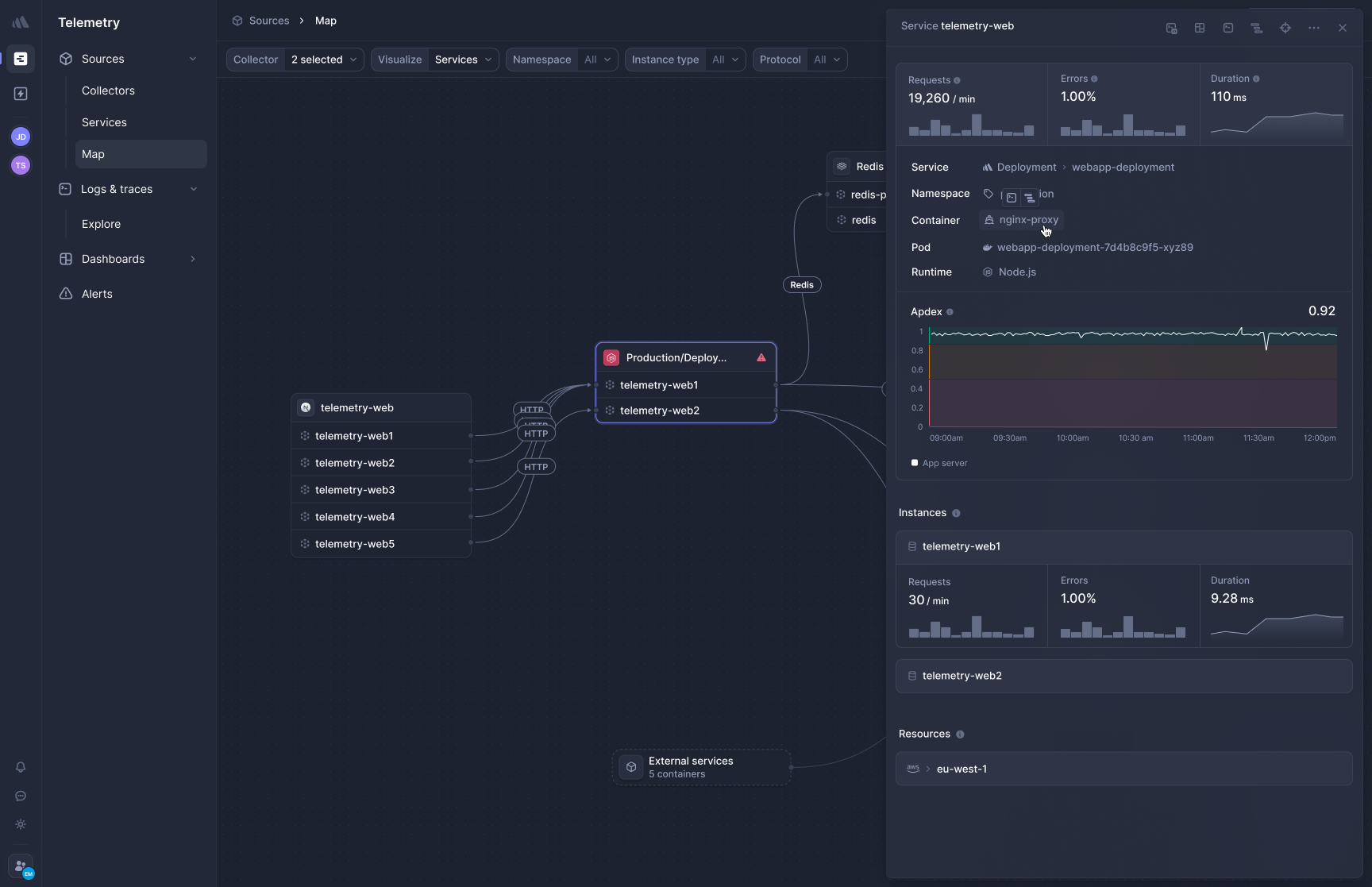
[Better Stack's APM](https://betterstack.com/tracing) captures traces at the kernel level via eBPF, meaning no SDKs, no per-service instrumentation, and no per-language maintenance. Here's how trace exploration works in practice:
Deploy the collector to Kubernetes, Docker, or Linux hosts, and HTTP/gRPC traffic between services is captured immediately. Database queries to PostgreSQL, MySQL, Redis, and MongoDB are traced automatically. The platform runs across Kubernetes, Docker, VMs, and serverless environments, not just K8s.
**Frontend-to-backend correlation** is native. A slow page load connects directly to the backend trace that caused it, across services and database calls, in one view. The RUM data sits in the same warehouse as the backend telemetry, so you're not stitching context across products.
**OpenTelemetry-native with zero lock-in.** Traces use the OTel wire format end to end. If you want to send the same data to another backend tomorrow, you change a config line, not your codebase. No proprietary SDK tax. What does that mean concretely? It means your instrumentation outlives your vendor choice.
### groundcover: eBPF APM, Kubernetes-first
groundcover's APM uses the same kernel-level capture approach. The eBPF sensor runs as a DaemonSet on your nodes and traces application traffic, database queries, and service-to-service calls automatically. groundcover also supports OpenTelemetry out of the box, positioning it against vendors that require proprietary agents.
Where it differs:
**Kubernetes is the primary target.** The platform supports any Kubernetes flavor from v1.21 and any Linux OS on AWS, including EKS, but the deployment model, metadata enrichment, and UI are all Kubernetes-centric. Non-K8s workloads work via Linux host connections, but you'll feel the K8s-first orientation throughout.
**Data stays in your VPC.** For regulated teams, this is a genuine advantage: full request and response payloads, including PII, can be inspected without data ever leaving your cloud boundary. This is something Better Stack's managed SaaS model cannot match unless you enable the optional S3 self-hosted data option.
**Frontend-to-backend correlation works via RUM.** groundcover's RUM SDK ties browser requests to backend traces, similar to Better Stack. The integration is solid, but it requires the RUM SDK to be installed in your frontend; it's not a unified kernel-level capture.
**Code-level profiling is not a core strength.** Like Better Stack, groundcover's eBPF approach captures network-level spans and database calls well but doesn't offer Datadog-style code-level CPU profiling. If that's a requirement, neither platform is your answer.
Is your primary concern that production telemetry never leaves your AWS account? groundcover is built for that. Is your primary concern a single unified platform that covers Kubernetes and everything else? Better Stack covers more ground.
[SCREENSHOT: groundcover APM trace view](https://imagedelivery.net/xZXo0QFi-1_4Zimer-T0XQ/c1c1ac97-abb5-4ee4-edd1-c0da21385f00/lg2x =2304x1181)
| APM feature | Better Stack | groundcover |
|-------------|--------------|-------------|
| **Instrumentation** | eBPF (zero code) | eBPF (zero code) |
| **Environments covered** | Kubernetes, Docker, VMs, serverless | Kubernetes-first + Linux hosts |
| **OpenTelemetry** | Native, no premium | Native, no premium |
| **Frontend-to-backend** | Unified in one warehouse | Via RUM SDK + backend correlation |
| **Data residency** | SaaS (optional S3 self-host) | BYOC (always in your VPC) |
| **Database tracing** | PostgreSQL, MySQL, Redis, MongoDB auto | PostgreSQL, MySQL, Redis, MongoDB auto |
| **Code-level profiling** | Not offered (network-level) | Not offered (network-level) |
## Log management
Both platforms solve the "indexing tax" problem that plagues Datadog and Splunk: all ingested logs are fully searchable, not tiered into indexed vs. archived. The differences sit in query languages, pricing shape, and where the data physically lives.
### Better Stack: SQL-first unified logs
[Better Stack logs](https://betterstack.com/logs) stores all logs as structured data alongside metrics and traces. All of it is immediately searchable. No indexing fees, no per-event charges, no picking which logs matter ahead of time. Here's Live Tail in action:
**SQL querying** is the primary interface. If you know SQL, you know Better Stack's log query language:
```sql
SELECT
service_name,
COUNT(*) as error_count,
AVG(duration_ms) as avg_duration
FROM logs
WHERE level = 'error'
AND timestamp > NOW() - INTERVAL '1 hour'
GROUP BY service_name
ORDER BY error_count DESC
```
The same SQL you use to query can also build charts and dashboards. Here's how that works:
**Pricing:** $0.10/GB ingestion + $0.05/GB/month retention. A service producing 100GB of logs per month costs $15 total. Because pricing is volume-based, doubling your log volume doubles the log bill (and nothing else), which is easier to forecast than groundcover's node-based pricing where log volume is "free" but nodes aren't.
### groundcover: volume-agnostic logs in your VPC
groundcover's logging pitch is simple: volume of logs, metrics, traces, and other observability data does not affect your cost. You pay per monitored node. If that node emits 1GB or 100GB per month, the license cost is identical. The tradeoff: your VPC hosting bill absolutely does change with volume, because you're running ClickHouse in your cloud and paying for the storage.
Log pipelines support OTTL-style processing, enrichment, and cross-linking between logs, traces, and Kubernetes objects for faster root cause analysis. Queries run through an embedded Grafana interface, and groundcover supports log patterns for deduplicating repetitive messages.
**Where groundcover shines:** high-volume, Kubernetes-native log workloads. If you're generating 10TB/month of logs from 200 nodes, groundcover's flat per-node model is compelling. You're paying the storage bill to your cloud provider directly, with no SaaS markup.
**Where it's weaker:** smaller clusters with moderate log volumes, where the per-node minimum makes the total cost higher than a volume-based competitor. Have you modeled what your actual log volume per node looks like? That's the number that determines which pricing model wins for you.

| Log management | Better Stack | groundcover |
|----------------|--------------|-------------|
| **Pricing model** | Volume-based ($0.10/GB ingest) | Per-node, volume-agnostic license |
| **Searchability** | 100% of ingested logs | 100% of ingested logs |
| **Query language** | SQL + PromQL | SQL + PromQL via embedded Grafana |
| **Log pipelines** | Vector-native, OTel collector | OTTL-style, Vector-based |
| **Data location** | Better Stack SaaS (or your S3) | Always in your VPC |
| **Best fit** | Small-to-mid clusters, mixed environments | High-volume K8s clusters, compliance-driven |
## Infrastructure monitoring
Cardinality is the silent killer of observability budgets. Both Better Stack and groundcover handle it better than Datadog, but through different mechanisms.
### Better Stack: no cardinality penalties, Prometheus-compatible
[Better Stack metrics](https://betterstack.com/infrastructure-monitoring) charges based on data volume, not unique metric combinations. Add tags freely. Here's the metrics view:
Better Stack is Prometheus-compatible with native PromQL support, and offers a drag-and-drop chart builder for teams who prefer not to write queries:
For high-cardinality metrics, understanding the tradeoffs still matters even without a pricing penalty:
### groundcover: VictoriaMetrics-backed with Prometheus compatibility

groundcover uses VictoriaMetrics for time-series storage, deployed in your VPC. It's Prometheus-compatible, supports PromQL natively, and handles high-cardinality workloads well because you're not paying per unique time series. The eBPF sensor auto-generates infrastructure metrics from kernel-level data (CPU, memory, disk, network per workload) and enriches them with Kubernetes metadata.
Standard integrations cover AWS, GCP, Azure, Kubernetes, Prometheus, and OpenTelemetry. Pipelines support global rate limits and incident-aware overrides to preserve fidelity during outages while controlling baseline volume.
**groundcover's metrics advantage:** kernel-level data that's hard to replicate with traditional agent-based tooling. Network flows, process-level resource usage, pod-to-pod traffic patterns; all automatic.
**Better Stack's advantage:** broader environment coverage. If half your fleet is on EC2 VMs and half on EKS, Better Stack treats them uniformly. groundcover's metrics sweet spot is Kubernetes-native workloads.
| Metrics feature | Better Stack | groundcover |
|-----------------|--------------|-------------|
| **Pricing model** | Volume-based | Per-node (unlimited metrics) |
| **Cardinality** | No penalty | No penalty |
| **Query language** | SQL + PromQL | PromQL + embedded Grafana |
| **Kernel-level metrics** | Yes (eBPF sensor) | Yes (eBPF sensor, K8s-enriched) |
| **Environment coverage** | K8s + Docker + VMs + serverless | K8s-first + Linux hosts |
| **Storage backend** | ClickHouse warehouse | VictoriaMetrics in your VPC |
## Incident management and on-call
Here's a category where the two platforms don't actually compete: groundcover doesn't offer incident management as a product. It offers monitors, alerts, and webhook-based integrations to incident.io, PagerDuty, Slack, and Microsoft Teams. Alerts go out the door to whatever tool owns your on-call rotation. Better Stack bundles that tool into the same platform.
This isn't groundcover being lazy. It's a deliberate scope choice. The company's focus is observability data. But if you're evaluating total cost of ownership, the incident management gap matters, because you still need a product to own escalation policies, phone/SMS alerts, and on-call scheduling.
### Better Stack: full incident management included
[Better Stack incident management](https://betterstack.com/incident-management) ships with on-call scheduling, escalation policies, unlimited phone and SMS alerts ($29/month per responder), Slack-native incident channels, and AI-powered investigation. Overview:
Most teams already work in Slack during incidents. Better Stack creates dedicated incident channels with investigation tools in-channel:
On-call rotations with timezone-aware schedules and automatic handoffs:
Automatic post-mortems generated from incident timelines:
And advanced escalation policies for enterprise workflows with multi-tier rules and metadata filters:
The result: one platform owns observability, alerting, on-call, and post-mortems. One invoice, one set of identities, one place to audit.
### groundcover: alerts that integrate with external incident tools

groundcover provides monitors (threshold, anomaly, deployment-aware), issue auto-aggregation that groups repeating problems into de-duplicated issues, and workflows for routing alerts. What it doesn't provide: on-call rotations, phone/SMS delivery, native incident channels, or post-mortem generation.
The typical pattern is routing alerts via webhook to incident.io, PagerDuty, Opsgenie, or Slack. incident.io runs roughly $16-40 per user/month. PagerDuty runs $21-41 per user/month at the team tiers and higher at enterprise. For a 5-responder team, that's $100-$400/month on top of groundcover's license.
**Are you currently paying for groundcover plus PagerDuty? That's two products, two vendors, two integrations to maintain. Better Stack collapses that into one**.
| Incident feature | Better Stack | groundcover |
|------------------|--------------|-------------|
| **Incident management** | Built-in | Not included (external integration) |
| **On-call scheduling** | Built-in | Via incident.io / PagerDuty |
| **Phone/SMS alerts** | Unlimited ($29/responder) | Via incident.io / PagerDuty |
| **Slack incident channels** | Native | Via incident.io / PagerDuty |
| **Post-mortems** | Automatic | Via incident.io / external tools |
| **Monthly cost (5 responders)** | $145 | $100-$400 (external tool) + groundcover license |
## Deployment and integration
Deployment is where the architectural choice between SaaS and BYOC shows up in day-to-day operations. Better Stack's collector ships and starts collecting. groundcover's model involves provisioning a backend inside your cloud account before the first byte is collected.
### Better Stack: Helm chart, collector, done
Deploy Better Stack's eBPF collector via Helm. It runs as a DaemonSet, auto-discovers services, and instruments databases and HTTP traffic without code changes. Here's the overview:
If you're already running OpenTelemetry, Better Stack integrates natively:
Many teams already use Vector for log processing. Better Stack integrates with that directly:
**Integrations:** 100+ covering all major stacks: MCP, OpenTelemetry, Vector, Prometheus, Kubernetes, Docker, PostgreSQL, MySQL, Redis, MongoDB, Nginx, and more. The [MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/) is generally available and lets Claude, Cursor, and other MCP clients query your observability data directly.
### groundcover: BYOC provisioning, then collector
groundcover deployment is a two-stage process. First, provision the backend in your AWS or GCP account (groundcover automates this via its control plane; the 14-day trial deploys a full BYOC instance in your own account with no node caps, no seat limits, and no gating). Then deploy the eBPF sensor via Helm:
```yaml
global:
groundcover_token:
backend:
enabled: false
ingress:
site:
clusterId: "your-cluster-name"
env: "your-environment-name"
```
Once provisioned, the sensor captures logs, metrics, traces, and Kubernetes events automatically. Integrations include OpenTelemetry, Prometheus, AWS, GCP, Azure, Slack, PagerDuty, Jira, and CI/CD tooling.
**The upfront cost:** provisioning time, VPC review with your cloud security team, and ongoing responsibility for the resources running in your account (even though groundcover manages them). For teams with strong cloud platform practices, this is fine. For smaller teams without dedicated platform engineering, it's a real overhead tax.
| Deployment aspect | Better Stack | groundcover |
|-------------------|--------------|-------------|
| **Time to production** | Minutes (Helm install) | Hours (BYOC + Helm) |
| **Cloud account changes** | None required | AWS/GCP IAM roles, VPC provisioning |
| **Code changes required** | Zero (eBPF) | Zero (eBPF) |
| **Ongoing infrastructure** | None | Monitor your VPC resources |
| **Trial reality** | Instant SaaS trial | Real BYOC deployment (14 days) |
## User experience and query interface
Both platforms moved beyond the product-silo problem that Datadog created. The question is how unified each UI actually is, and how productive new users become in the first week.
### Better Stack: one interface, one query language
Better Stack presents logs, metrics, and traces in a single UI with SQL as the common query language and PromQL for metrics. Alerts surface the service map, related logs, metric anomalies, and trace samples in one view. Customize the Live Tail workspace to fit your workflow:
Investigation workflow: alert → single view with service map, logs, metrics, traces → click through. Most investigations resolve in 2-3 clicks because there's no product-switching involved.
### groundcover: unified UI with embedded Grafana

groundcover's UI presents logs, metrics, traces, and issues in one interface. The platform embeds Grafana for dashboards and querying, which gives users familiar tooling. Service maps, trace views, and log explorers are unified.
One honest caveat from user reviews: groundcover's UX and dashboard experience can feel restrictive on complex views, with limited dashboard customization, such as non-resizable panels and less flexible layouts. This has improved in recent releases, but if deep dashboard customization is a hard requirement, it's worth evaluating during a trial.
Where groundcover really leads: Issues auto-aggregation that represents many identical repeating incidents as a single velocity-tracked issue. Instead of drowning in thousands of duplicate alerts, you see the pattern, the first-seen timestamp, and the trend. It's a real workflow improvement.
| UX aspect | Better Stack | groundcover |
|-----------|--------------|-------------|
| **Query language** | SQL + PromQL | SQL + PromQL via Grafana |
| **Context switching** | None (unified UI) | None (unified UI) |
| **Dashboard customization** | Native + SQL-built | Embedded Grafana |
| **Issue aggregation** | Yes (error tracking) | Yes (first-class Issues feature) |
| **Onboarding time** | Hours | Hours-to-days |
## AI SRE and MCP
This is the category where both companies have shipped substantial AI investment in the past year, and where they differentiate in interesting ways.
### Better Stack: AI SRE and generally-available MCP
**AI SRE** activates autonomously during incidents. It analyzes the service map, queries logs, reviews recent deployments, and proposes likely root causes without manual prompting. At 3am, that means you start from a hypothesis instead of from scratch.
**[Better Stack MCP server](https://betterstack.com/docs/getting-started/integrations/mcp/)** connects your AI assistant (Claude, Cursor, or any MCP-compatible client) directly to your observability data. Instead of copying log snippets into a chat window, your AI assistant queries Better Stack directly, running ClickHouse SQL against your logs, checking who's on-call, acknowledging incidents, or building charts through natural language.
Setup is a single config block:
```json
{
"mcpServers": {
"betterstack": {
"type": "http",
"url": "https://mcp.betterstack.com"
}
}
}
```
The MCP server covers uptime monitoring, incident management, log querying, metrics, dashboards, error tracking, and on-call scheduling. You can allowlist specific tools for read-only access or blocklist destructive operations.
### groundcover: AI Mode on Bedrock and MCP server

groundcover AI Mode, announced generally available in March 2026 at KubeCon Amsterdam, runs natively within the customer's AWS infrastructure via Amazon Bedrock, ensuring logs, traces, and production telemetry never leave the customer's environment. This is a meaningfully differentiated approach for compliance-driven teams: the AI inference itself happens inside your AWS account.
Customers pay Amazon Bedrock token costs directly and can set usage limits by user or team. The architectural bet is that BYOC AI matters for the same reason BYOC observability matters: regulated teams can't ship production data to third-party AI endpoints.
The practical difference groundcover emphasizes: AI Mode can answer questions that are structurally impossible with instrumentation-dependent approaches, because eBPF captures telemetry even for services that were never manually instrumented with OpenTelemetry.
**groundcover MCP Server** connects AI assistants like Cursor and Claude Code to your observability data. The MCP server is still in active development ("Work in progress. We keep adding tools and polishing the experience"), with capabilities for querying logs, traces, metrics, events, and Kubernetes resources directly from AI agents.
The honest comparison: both platforms have production-ready MCP. Better Stack's MCP is GA and covers a broader product surface (because Better Stack has a broader product surface, including incident management and on-call). groundcover's AI Mode running on Bedrock is a meaningfully novel compliance-preserving architecture that Better Stack does not match.
| AI capability | Better Stack | groundcover |
|---------------|--------------|-------------|
| **AI SRE / investigation** | Yes (AI SRE, autonomous) | Yes (AI Mode, GA on Bedrock) |
| **MCP server** | Yes (GA, all customers) | Yes (active development) |
| **AI inference location** | Better Stack cloud | Inside your AWS account (Bedrock) |
| **AI coding integration** | Claude Code + Cursor | Claude Code + Cursor |
| **Natural language queries** | Via MCP in any AI client | Via MCP + native UI |
| **Compliance-preserving AI** | Standard SaaS boundaries | BYOC AI (data + inference in VPC) |
## Real user monitoring
Both platforms now ship RUM, and both price it dramatically lower than Datadog. groundcover's differentiation is that RUM data stays in your VPC alongside the backend telemetry. Better Stack's differentiation is that RUM is part of the same unified pricing model as everything else.
### Better Stack: unified RUM at volume-based pricing

Better Stack RUM captures frontend sessions, JavaScript errors, Core Web Vitals, user behavior analytics, and session replay. Because it sits in the same warehouse as your backend telemetry, **frontend events, errors, and backend traces are queryable with the same SQL syntax in the same interface**.
**Session replay** plays back user interactions at 2x speed with automatic pause-skipping. Sensitive fields are excluded at the SDK level. Rage clicks, dead clicks, and errors are surfaced as filters.
**Website analytics** tracks referrers, UTM campaigns, entry/exit pages, locales, and screen resolutions in real time. **Web Vitals** (LCP, CLS, INP) are tracked per URL with alerting when performance degrades.
**Product analytics** captures user events with funnel analysis auto-generated after the fact, so you don't have to pre-instrument events before you know what questions to ask.
**Error tracking is built in.** Session replays link directly to JavaScript errors and backend traces that occurred during the session. The one-click Claude Code / Cursor prompts that work for backend errors work here too.
**Pricing:** $0.00150/session replay, included in the same volume-based model as logs and metrics.
### groundcover: BYOC RUM with backend correlation

groundcover's RUM capability brings frontend observability into the same BYOC model as backend telemetry, allowing end-to-end correlation and visibility over the entire user experience. A lightweight JavaScript SDK collects network requests, front-end logs, performance metrics including Core Web Vitals, user interactions, and custom events. Session recording is available, with sensitive element masking configurable via HTML attributes.
groundcover RUM includes native integration with backend observability data: client-side traces from browser network requests are automatically correlated with server-side traces captured by groundcover's eBPF instrumentation. When a user triggers an API call, you see the complete distributed trace from browser to backend in one view.
**The BYOC advantage for RUM is real.** Real User Monitoring data is rich with user details: page URLs, user IDs or emails, behavior patterns, potentially form inputs. SaaS monitoring tools by definition send all that data to a third-party cloud. groundcover's BYOC deployment means that data never leaves your infrastructure. For regulated industries, that's a meaningful compliance posture.
**The tradeoff:** RUM pricing is folded into the per-node license. You don't pay per-session, but you also can't run RUM independently of your Kubernetes nodes. If you have a small backend but massive frontend traffic, the math may not favor groundcover.
| RUM feature | Better Stack | groundcover |
|-------------|--------------|-------------|
| **Availability** | GA | GA |
| **Session replay** | Yes | Yes |
| **Core Web Vitals** | LCP, CLS, INP | LCP, CLS, INP |
| **Data location** | Better Stack SaaS | Inside your VPC |
| **Backend correlation** | Unified warehouse, same SQL | eBPF trace correlation |
| **Mobile SDK** | Web (mobile coming) | Web |
| **Pricing model** | Per-session volume-based | Included in per-node license |
| **Best fit** | Mixed infra, simple pricing | Regulated, K8s-first, high session volume |
## LLM observability
This is one category where groundcover has clearly moved first. It's worth acknowledging that directly.
### groundcover: eBPF-based LLM observability

groundcover monitors every interaction with LLMs, capturing full payloads, token usage, latency, throughput, and error patterns. It captures behavior, allowing teams to follow the reasoning path of a failed output, investigate prompt drift across a session, or isolate where a tool call introduced latency. groundcover positions itself as the only eBPF-based platform to achieve full visibility into API request and response for LLM calls, allowing observability and security practitioners to monitor content sent to third-party LLM providers.
Out-of-the-box LLM tracing for OpenAI and Anthropic is available from sensor version 1.9.563, with Bedrock support from 1.11.158. groundcover automatically transforms captured traffic into structured spans that adhere to OpenTelemetry GenAI Semantic Conventions, so your LLM traces correlate with existing application telemetry.
Because LLM payloads often contain sensitive data (PII, secrets), groundcover supports configurable field obfuscation while keeping metadata like model and token counts visible. The BYOC architecture ensures prompt content never leaves your cloud, which matters for teams running compliance-sensitive LLM workloads.
### Better Stack: OpenTelemetry-compatible LLM observability
Better Stack does not ship a dedicated LLM observability product at the same depth. Because Better Stack ingests OpenTelemetry natively, teams instrumenting with OpenTelemetry GenAI Semantic Conventions via the OpenAI or LangChain instrumentation libraries can send those spans to Better Stack and query them alongside other traces.
If end-to-end LLM observability with zero instrumentation is a hard requirement (particularly for unmodified third-party LLM calls), groundcover has a genuine edge here. This is one of the clearest cases in the comparison where groundcover's eBPF-based capture does something Better Stack's product doesn't match today.
| LLM observability | Better Stack | groundcover |
|-------------------|--------------|-------------|
| **Dedicated product** | No (OTel ingest) | Yes (eBPF-based) |
| **Zero-instrumentation capture** | No | Yes |
| **Full payload visibility** | Via OTel spans | Yes (eBPF) |
| **OpenAI, Anthropic, Bedrock** | Via OTel SDKs | Native eBPF auto-detection |
| **PII obfuscation** | Via OTel processors | Native configuration |
| **Data residency** | SaaS | Always in your VPC |
## Status pages and customer communication
Another category where the products don't overlap: groundcover doesn't ship status pages. Better Stack does.
### Better Stack: built-in status pages
[Better Stack Status Pages](https://betterstack.com/status-pages) is included with the platform and syncs automatically with incident management:
Capabilities include public and private status pages, custom branding, real-time incident updates auto-synced with internal incidents, subscriber notifications across email, SMS, Slack, and webhook, scheduled maintenance announcements, and multi-language support. Advanced features add custom CSS, password protection, SAML SSO, and metadata-driven service organization. Pricing: $12-208/month for advanced features.
### groundcover: status pages not included
**groundcover has no status page product**. Teams pair it with Atlassian Statuspage ($29-1,499/month), Instatus, or a homegrown page. That's another vendor, another integration, another invoice. If customer-facing status communication is part of your reliability posture (and for most SaaS businesses, it is), this gap matters.
| Status pages | Better Stack | groundcover |
|--------------|--------------|-------------|
| **Availability** | Built-in | Not included |
| **Incident sync** | Automatic | Via third-party tool |
| **Subscriber channels** | Email, SMS, Slack, webhook | Via third-party tool |
| **Private pages** | Password, SSO, IP allowlist | Via third-party tool |
| **Monthly cost** | $12-208 (transparent) | Separate vendor ($29+) |
## Error tracking
Better Stack ships a dedicated, Sentry-compatible error tracking product. groundcover surfaces errors within its Issues and Logs views, but doesn't market a separate error tracking product.
### Better Stack: Sentry-compatible error tracking

[Better Stack Error Tracking](https://betterstack.com/error-tracking) accepts Sentry SDK payloads directly, so you can migrate from Sentry without rewriting instrumentation. AI-native debugging includes Claude Code and Cursor integrations with pre-made prompts that summarize error context. Copy the prompt, paste into your AI coding agent, resolve the issue. Full distributed trace context for each error is captured automatically.
### groundcover: Issues as built-in error surface
groundcover's Issues are auto-detected and aggregated, representing many identical repeating incidents. The smart aggregation mechanism identifies query parameters, removes them, and groups stripped queries and API URIs into patterns, allowing users to easily identify and isolate the root cause of a problem. Each issue is assigned a velocity graph showing its behavior over time and a live counter.
This is powerful for traffic-driven errors (failed API calls, database errors, status code patterns). It's less powerful for traditional application exceptions with stack traces, where Sentry-style workflows (release tracking, source maps, IDE integration) are the norm. If your team already lives in Sentry, Better Stack's drop-in compatibility is a zero-friction migration. If you don't use Sentry today, groundcover's Issues approach may cover what you need.
| Error tracking | Better Stack | groundcover |
|----------------|--------------|-------------|
| **Dedicated product** | Yes | Surfaced via Issues |
| **Sentry SDK compatibility** | Drop-in | No |
| **Distributed trace context** | Automatic | Via trace linking |
| **AI debugging** | Claude Code + Cursor prompts | Via AI Mode |
| **Source map support** | Yes | Via RUM source maps |
| **Release tracking** | Yes | Not a primary workflow |
## Enterprise readiness
Both platforms are SOC 2 Type II compliant and suitable for enterprise use, but they approach enterprise differently. groundcover's BYOC model naturally satisfies some compliance requirements that Better Stack's managed SaaS has to address through certifications and contractual controls.
Better Stack covers SOC 2 Type II, GDPR, SSO via Okta/Azure/Google, SCIM provisioning, RBAC, audit logs, EU and US data residency, optional self-hosted data in your S3 bucket, a dedicated Slack support channel, and a named account manager. Data centers are DIN ISO/IEC 27001 certified. Regular third-party penetration testing with reports available to enterprise customers.
groundcover covers SOC 2 Type II, ISO 27001, SSO, RBAC (on Enterprise tier), audit logs, and inherent data residency through BYOC. The on-premise deployment option extends to fully air-gapped environments, which is a genuine advantage for government, defense, and regulated industries that cannot use SaaS at all.
| Enterprise feature | Better Stack | groundcover |
|--------------------|--------------|-------------|
| **SOC 2 Type II** | ✓ | ✓ |
| **ISO 27001** | Data centers certified | ✓ (product level) |
| **GDPR** | ✓ | ✓ |
| **SSO (SAML/OIDC)** | ✓ | ✓ |
| **SCIM provisioning** | ✓ | ✓ |
| **RBAC** | ✓ | ✓ (Enterprise tier) |
| **Audit logs** | ✓ | ✓ |
| **Data residency** | EU + US + optional S3 self-host | Always in your VPC |
| **Air-gapped deployment** | No | Yes (On-Prem tier) |
| **Dedicated support** | Slack channel + account manager | Premium support (Enterprise) |
| **Self-hosted data** | Optional (your S3) | Default (your VPC) |
## Final thoughts
The decision ultimately comes down to **data residency, infrastructure complexity, and how many tools you want to manage**.
If your telemetry must remain داخل your cloud or you operate a strictly Kubernetes-first environment, groundcover is a solid choice. Its BYOC model is especially relevant for **compliance-heavy use cases** and teams comfortable managing their own infrastructure.
However, for most teams, **Better Stack stands out as the more complete and practical solution**. It delivers the same modern observability foundation, including eBPF and OpenTelemetry, while also **combining incident management, on-call scheduling, status pages, error tracking, and uptime monitoring in one platform**. This means **fewer vendors, lower operational overhead, and a faster path from alert to resolution**.
In addition, Better Stack’s **volume-based pricing with no per-node costs and no BYOC infrastructure burden** makes it easier to predict and control spend, especially for teams running mixed environments beyond Kubernetes.
As a result, **Better Stack is the better default choice for most organizations**, particularly those that value simplicity, speed, and an all-in-one reliability platform.
You should still evaluate your specific workload. **High data volume with fewer nodes may favor groundcover**, while **most real-world setups with mixed infrastructure will benefit from Better Stack**.
Ready to see the difference? [Start your free trial](https://betterstack.com) or compare pricing side by side to see which model fits your workload.